64 KiB

图结构篇
图结构在我们的生活中实际上是非常常见的,其中最显著的就是我们的地图了,比如我的家乡重庆:
可以看到,地图盘根错节,错综复杂,不同的道路相互连接,我们可以自由地从这些道路通过,从一个地点到达另一个地点。当然除了地图,我们的计算机网络、你的人际关系网等等,这些都可以用图结构来表示。图结构也是整个数据结构中比较难的一部分,而这一章,我们将探讨图结构的性质与应用。
图也是由多个结点连接而成的,但是一个结点可以同时连接多个其他结点,多个结点也可以同时指向一个结点,跟我们之前讲解的树结构不同,它是一种多对多的关系:
它比树形结构更加复杂,没有明确的层次关系,结点与结点之间的连接关系更加自由,图结构是任意两个数据对象之间都有可能存在某种特定关系的数据结构。
基本概念
图(Graph)一般由两个集合共同构成,一个是非空但是有限的顶点集合V(Vertex),另一个是描述顶点之间连接关系的边集合E(Edge,边集合可以为空集,比如只有一个顶点的情况下,没得连啊),一个图实际上正是由这些结点(顶点)和对应的边组成的。因此,图可以表示为:G = (V, E)
比如一个图我们可以表示为,集合$V = {A,B,C,D}$,集合$E = {(A,B),(B,C),(C,D),(D,A),(C,A)}$,图有两种基本形式,一种是上面那样的有向图(有向图表明了方向,从哪个点到哪个点),还有一种是无向图(无向图仅仅是连接,并不指明方向),比如我们上面这样表示就是一个无向图:
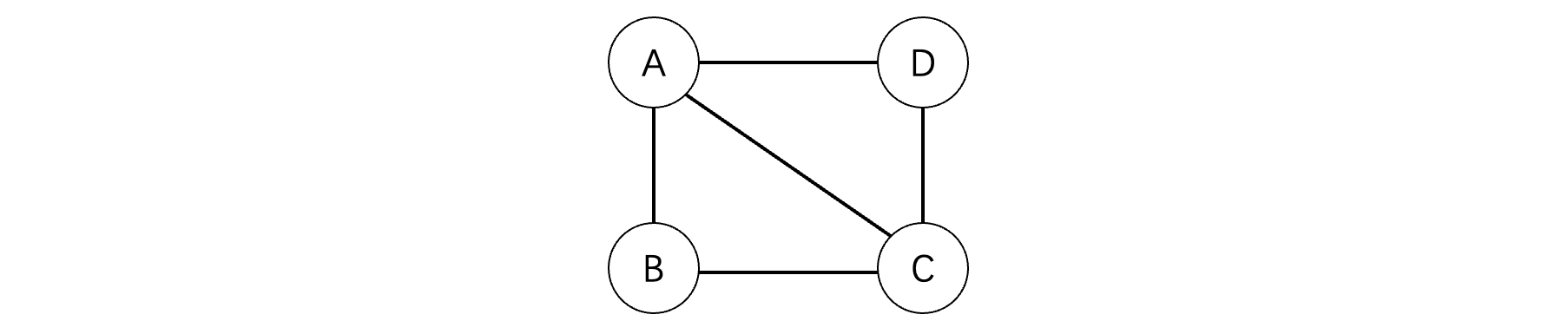
每个结点的度就是与其连接的边数,每条边是可以包含权值的,当前也可以不包含。
当然我们也可以将其表示为有向图,集合$V = {A,B,C,D}$,集合$E = {<A,B>,<B,C>,<C,D>,<D,A>,<C,A>}$注意有向图的边使用尖括号<>表示。比如上面这个有向图,那么就长这样:
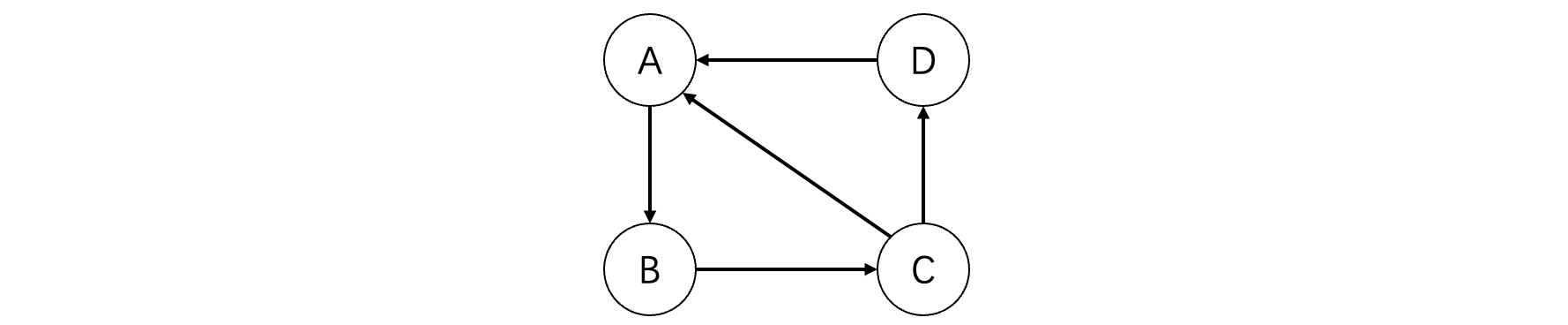
如果是无向图的一条边(A,B),那么就称A、B互为邻接点;如果是有向图的一条边<A,B>,那么就称起点A邻接到终点B。有向图的每个结点分为入度和出度,其中入度就是与顶点相连且指向该顶点的边的个数,出度就是从该顶点指向邻接顶点的边的个数。
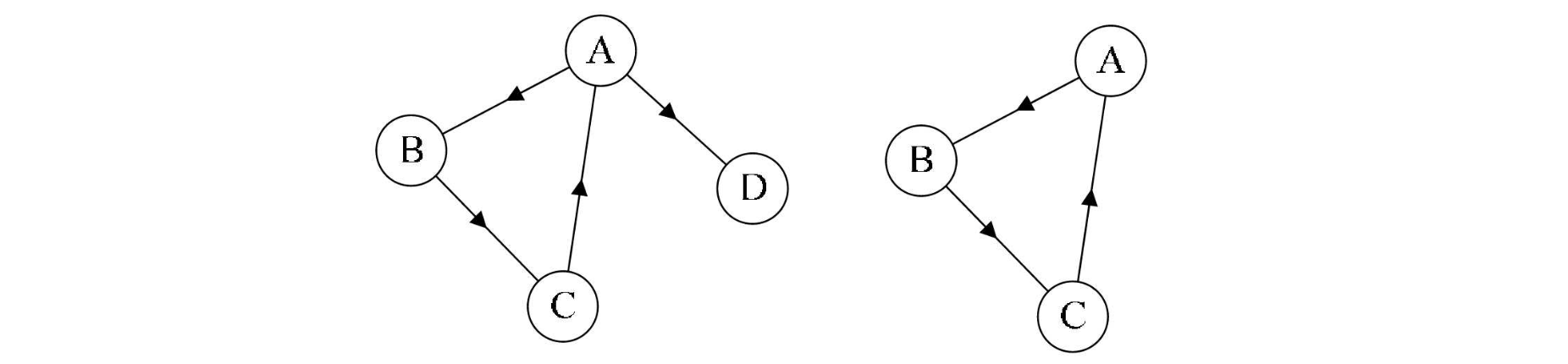
只要我们的图中不出现自回路边或是重边,那么我们就可以称这个图为简单图,比如上面两张图都是简单图。而下面的则是典型的非简单图了,其中图一出现了自回路,而图二出现了重边:
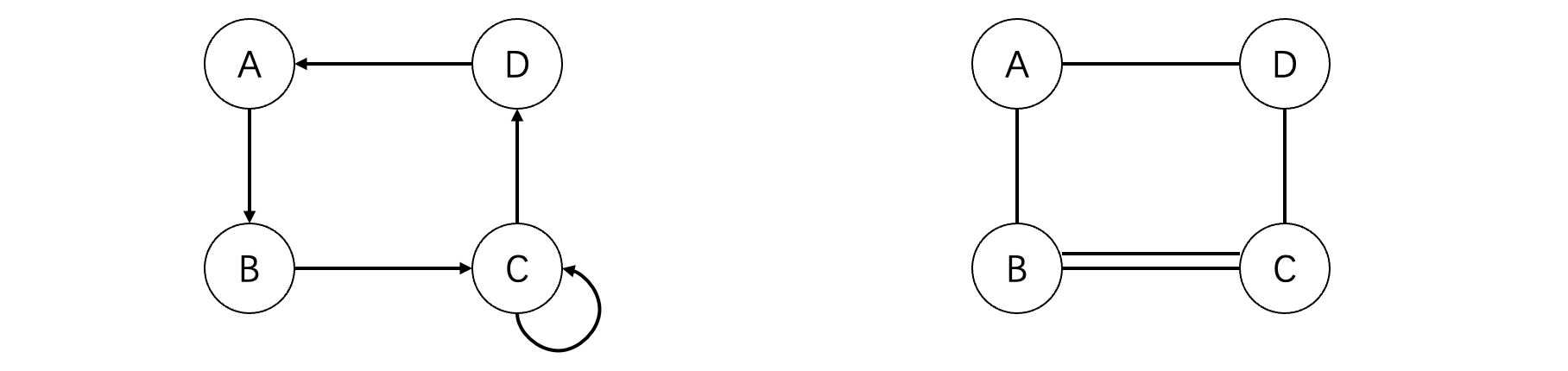
如果在一个无向图中,任意两个顶点都有一条边相连,则称该图为无向完全图:
同样的,在一个有向图中,如果任意两顶点之间都有由方向互为相反的两条边连接,则称该图为有向完全图:
图通过边将顶点相连,这样我们就可以从一个顶点经过某条路径到达其他顶点了,比如我们现在想要从下面的V5点到达V1点:
那么我们可以有很多种路线,比如经过V2到达,经过V3到达等:
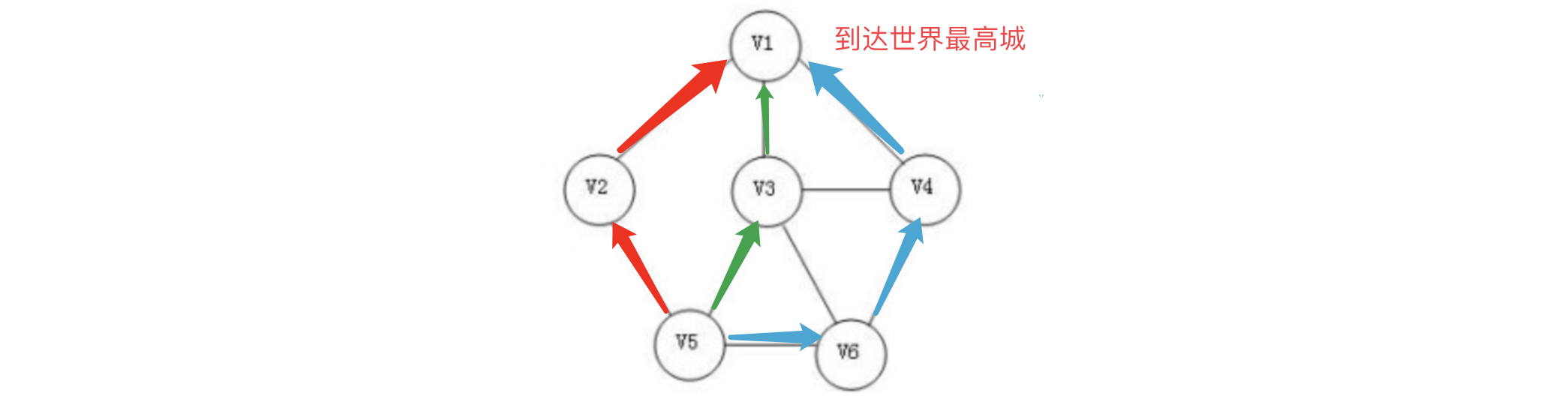
在一个无向图中,如果从一个顶点到另一个顶点有路径,那么就称这两个顶点是连通的。可以看到,要从V5到达V1我们可以有很多种选择,从V5可以到达V1(当然也可以反着来),所以,我们称V5和V1连通的。特别的,如果图中任意两点都是连通的,那么我们就称这个图为连通图。对于有向图,如果图中任意顶点A和B,既有从A到B的路径,也有B到A的路径,则称该有向图是强连通图。
对于图 G = (V, E) 和 $G' = (V', E')$,若满足 V' 是 V 的子集,并且 E' 是 E 的子集,则称 G' 是 G 的子图,比如下面的两个图:
其中右边的图就满足上述性质,所以说右边的图是左边图的子图。
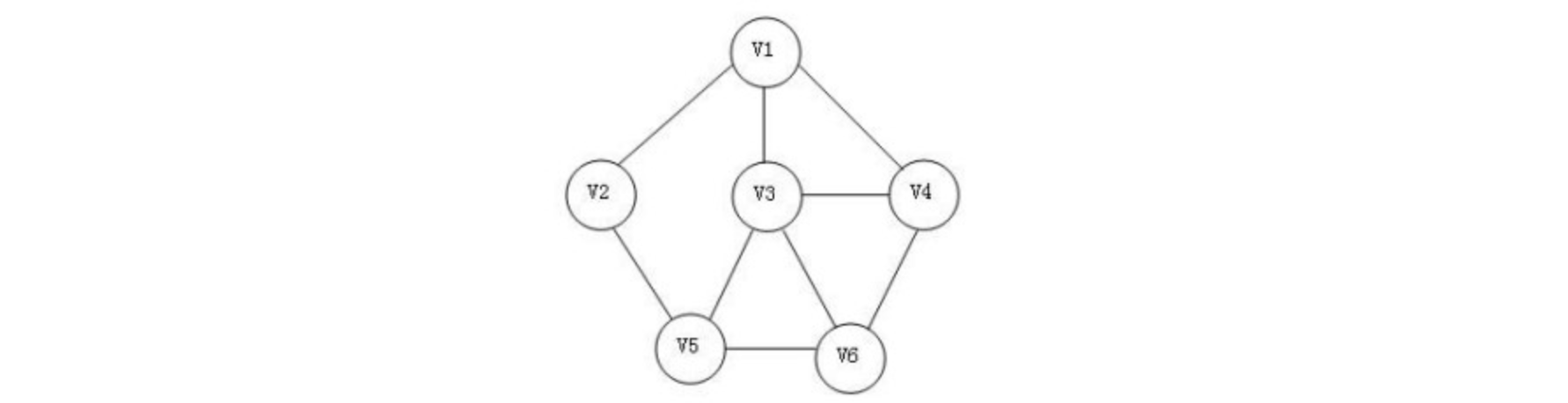
无向图的极大连通子图称为连通分量,有向图的极大连通子图称为强连通分量。那么什么是极大连通子图呢?首先连通子图就是原图的子图,并且子图也是连通图,同时应该具有最大的顶点数,即再加入原图中的其他顶点会导致子图不连通,拥有极大顶点数的同时也要包含依附于这点顶点所有的边才行,比如:
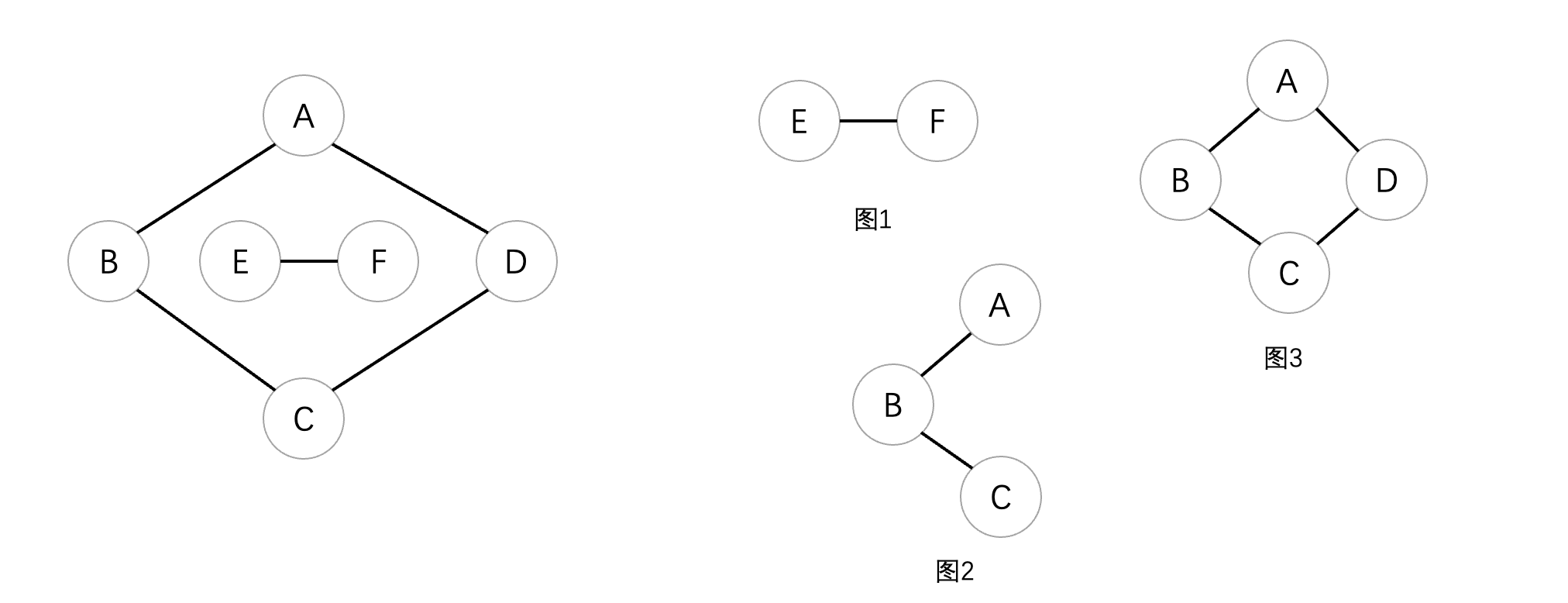
可以看到右侧图1、2、3都是左图的子图,但是它们并不都是原图的连通分量,首先我们来看图1,它也是一个连通图,并且包含极大顶点数和所有的边(也就是原图内部的这一块)所以说它是连通分量,我们接着来看图2,它虽然也是连通图,但是并没有包含极大顶点数(最多可以吧D也给加上,但是这里没加)所以说并不是。最后来看图3,它也是连通图,并且包含了极大顶点数和边,所以说是连通分量。
- 原图为连通图,那么连通分量就是其本身,有且仅有一个。
- 原图为非连通图,那么连通分量会有多个。
对于极小连通子图,我们会在后面的生成树部分进行讲解。
存储结构
前面我们介绍了图的一些基本概念,我们接着来看如何在程序中对图结构进行表示,这一部分可能会涉及到某些在《线性代数》这门课程中出现的概念。
邻接矩阵
邻接矩阵实际上就是用矩阵去表示图中各顶点之间的邻接关系和权值。假设有一个图 $G = (V, E)$,其中有N个顶点,那么我们就可以使用一个N×N的矩阵来表示,比如下面有A、B、C、D四个顶点的图:
此时我们需要使用邻接矩阵来表示它,就像下面这样:
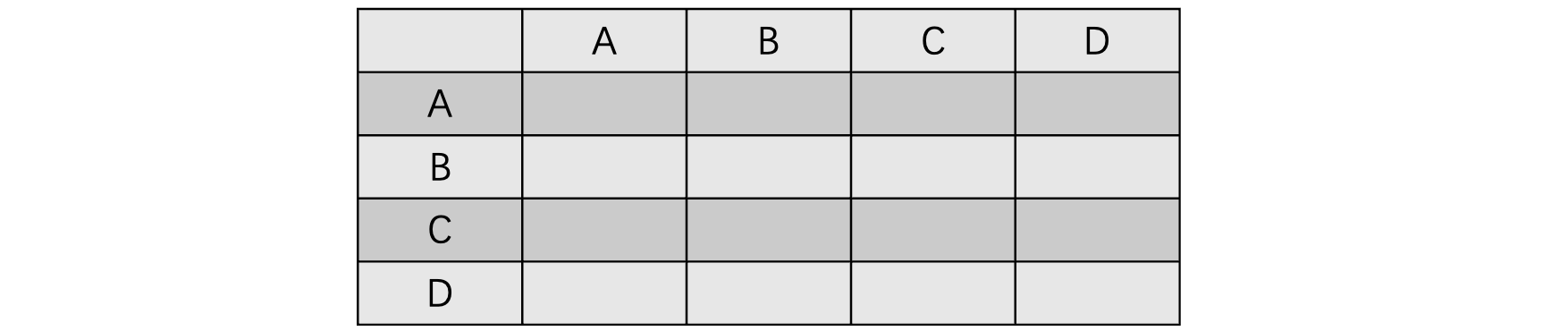
对于一个不带权值的图来说:
G_{ij} = \begin{cases}
1, 无向图的(v_i,v_j)或有向图的<v_i,v_j>是图中的边\\
0, 无向图的(v_i,v_j)或有向图的<v_i,v_j>不是图中的边
\end{cases}
对于一个带权值的图来说,如果有边,则直接填写对应边的权值,如果没有,那么就填写0或是∞(因为某些图会认为0也是权值,所以说可以用∞,它可以是一个计算机允许的最大值大于所有边的权值的数)来进行表示:
G_{ij} = \begin{cases}
w_{ij}, 无向图的(v_i,v_j)或有向图的<v_i,v_j>是图中的边\\
0或∞, 无向图的(v_i,v_j)或有向图的<v_i,v_j>不是图中的边
\end{cases}
所以说,对于上面的有向图,我们应该像这样填写:
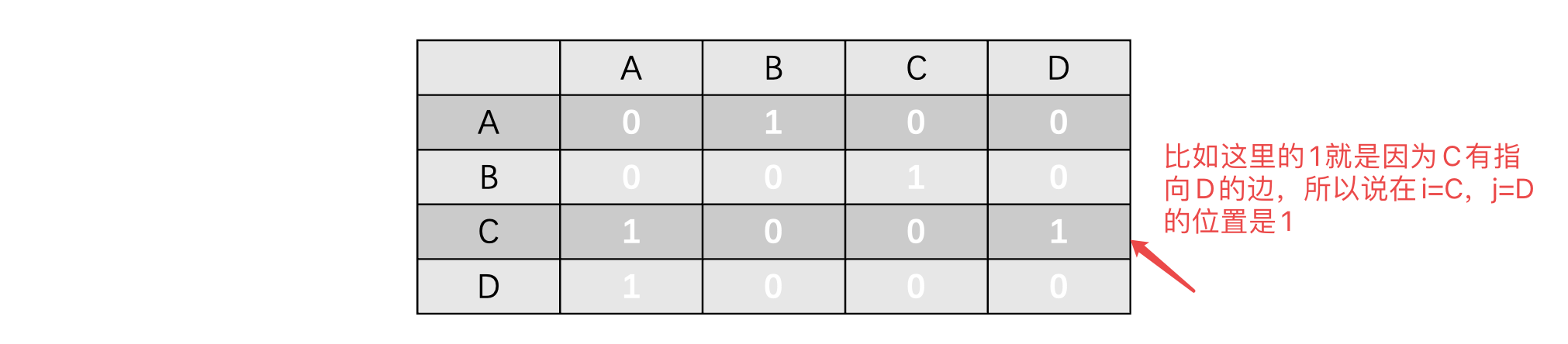
那么我们来看看无向图的邻接矩阵呢?比如下面的这个图:
对于无向图来说,一条边两边是相互连接的,所以说,A连接B,那么B也连接A,所以说就像这样:

可以看到得到的矩阵用我们在《线性代数》中的定义来说就是一个对称矩阵(上半和下半都是一样的)因为没有自回路顶点,所以说主对角线上的元素全都是0。由于无向图没有方向之分,顶点之间是相互连接的,所以说无向图的邻接矩阵必定是一个对称矩阵。
我们可以来总结一下性质:
- 无向图的邻接矩阵一定是一个对称矩阵,因此,有时为了节省时间,我们可以只存放上半部分。
- 对于无向图,邻接矩阵的第
i行非0(或非∞)的个数就是第i个顶点的度。 - 对于有向图,邻接矩阵的第
i行非0(或非∞)的个数就是第i个顶点的出度(纵向就是入度了)
接着我们来看看如何通过代码实现,首先我们需要对结构体进行一下定义,这里我们以有向图为例:
#define MaxVertex 5
typedef char E; //顶点存放的数据类型,这个不用我多说了吧
typedef struct MatrixGraph {
int vertexCount; //顶点数
int edgeCount; //边数
int matrix[MaxVertex][MaxVertex]; //邻接矩阵
E data[MaxVertex]; //各个顶点对应的数据
} * Graph;
接着我们可以对其进行一下初始化创建后返回:
Graph create(){ //创建时,我们可以指定图中初始有多少个结点
Graph graph = malloc(sizeof(struct MatrixGraph));
graph->vertexCount = 0; //顶点和边数肯定一开始是0
graph->edgeCount = 0;
for (int i = 0; i < MaxVertex; ++i) //记得把矩阵每个位置都置为0
for (int j = 0; j < MaxVertex; ++j)
graph->matrix[i][j] = 0;
return graph;
}
int main(){
Graph graph = create(); //这里咱们就搞一个
}
接着我们就可以编写一下添加顶点和添加边的函数了:
void addVertex(Graph graph, E element){
if(graph->vertexCount >= MaxVertex) return;
graph->data[graph->vertexCount++] = element; //添加新元素
}
void addEdge(Graph graph, int a, int b){ //添加几号顶点到几号顶点的边
if(graph->matrix[a][b] == 0) {
graph->matrix[a][b] = 1; //注意如果是无向图的话,需要[a][b]和[b][a]都置为1
graph->edgeCount++;
}
}
我们来尝试构建一下这个有向图:
Graph graph = create();
for (int c = 'A'; c <= 'D' ; ++c)
addVertex(graph, (char) c);
addEdge(graph, 0, 1); //A -> B
addEdge(graph, 1, 2); //B -> C
addEdge(graph, 2, 3); //C -> D
addEdge(graph, 3, 0); //D -> A
addEdge(graph, 2, 0); //C -> A
接着我们打印此领接矩阵,看看是否变成了我们预想中的那样:
void printGraph(Graph graph){
for (int i = -1; i < graph->vertexCount; ++i) {
for (int j = -1; j < graph->vertexCount; ++j) {
if(j == -1)
printf("%c", 'A' + i);
else if(i == -1)
printf("%3c", 'A' + j);
else
printf("%3d", graph->matrix[i][j]);
}
putchar('\n');
}
}
最后得到:

可以看到结果跟我们上面推导得出的邻接矩阵一模一样,当然这里仅仅是演示了普通的有向图,我们也可以稍微将代码进行修改,将其变成一个无向图或是带权有向图,这里就不做演示了。
邻接表
前面我们介绍了领接矩阵,我们可以使用邻接矩阵在程序中保存一个图的边相关信息,它采用二维数组的形式,将对应边的连接关系进行存储,但是我们知道,数组存在容量上的局限性(学了这么多节课了,应该能体会到,数组需要一段连续空间,无论是申请还是用起来都很麻烦)同时,我们创建邻接矩阵后,如果图的边数较多(稠密图)利用率还是挺高的,但是一旦遇到边数很少的图(稀疏图)那么表中大量的位置实际上都是0,根本没有被利用起来,是很浪费的。
此时,我们可以考虑使用链式结构来解决这种问题,就像下面这样:
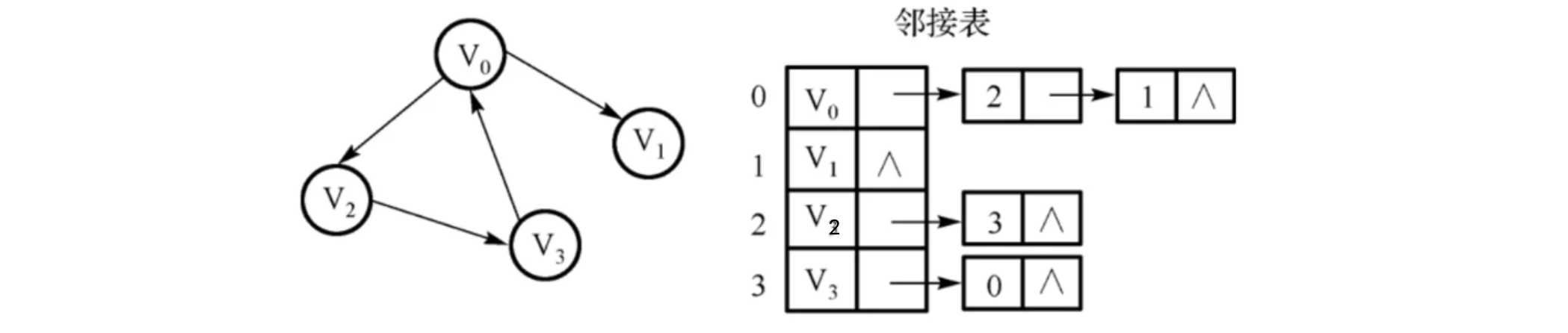
对于图中的每个顶点,建立一个数组,存放一个头结点,我们将与其邻接的顶点,通过一个链表进行记录(看着挺像前面讲的哈希表)这样,也可以表示一个图的连接关系,并且内存空间能够得到更加有效的利用。当然,对于无向图来说,跟之前一样,两边都需要进行保存:
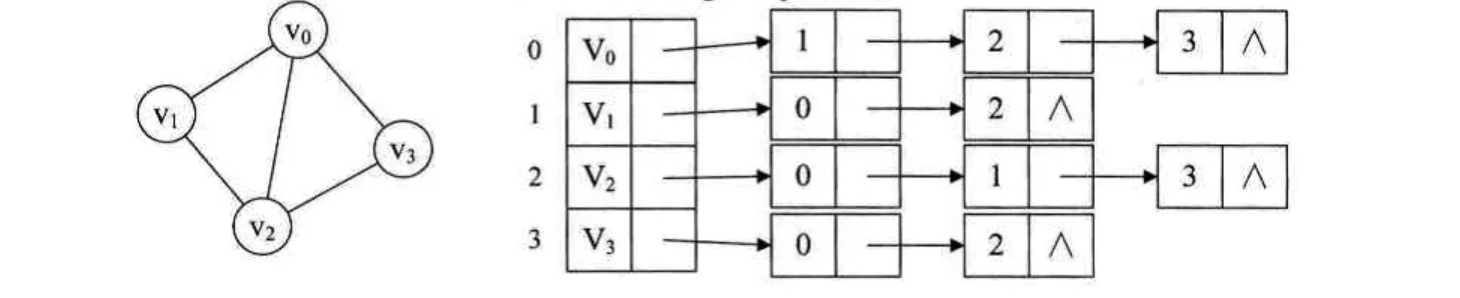
我们来尝试编写一下代码实现,首先还是定义:
#define MaxVertex 5
typedef char E;
typedef struct Node { //结点和头结点分开定义,普通结点记录邻接顶点信息
int nextVertex;
struct Node * next;
} * Node;
struct HeadNode { //头结点记录元素
E element;
struct Node * next;
};
typedef struct AdjacencyGraph {
int vertexCount; //顶点数
int edgeCount; //边数
struct HeadNode vertex[MaxVertex];
} * Graph;
接着是对其进行初始化:
Graph create(){ //创建时,我们可以指定图中初始有多少个结点
Graph graph = malloc(sizeof(struct AdjacencyGraph));
graph->vertexCount = graph->edgeCount = 0;
return graph; //头结点数组一开始可以不用管
}
在添加边和顶点时,稍微麻烦一些:
void addVertex(Graph graph, E element){
if(graph->vertexCount >= MaxVertex) return; //跟之前一样
graph->vertex[graph->vertexCount].element = element; //添加新结点时,再来修改也行
graph->vertex[graph->vertexCount].next = NULL;
graph->vertexCount++;
}
void addEdge(Graph graph, int a, int b){
Node node = graph->vertex[a].next;
Node newNode = malloc(sizeof(struct Node));
newNode->next = NULL;
newNode->nextVertex = b;
if(!node) { //如果头结点下一个都没有,那么直接连上去
graph->vertex[a].next = newNode;
} else { //否则说明当前顶点已经连接了至少一个其他顶点了,有可能会出现已经连接过的情况,所以说要特别处理一下
do {
if(node->nextVertex == b) return; //如果已经连接了对应的顶点,那么直接返回
if(node->next) node = node->next; //否则继续向后遍历
else break; //如果没有下一个了,那就找到最后一个结点了,直接结束
} while (1);
node->next = newNode;
}
graph->edgeCount++; //边数计数+1
}
我们来将其构建一下吧,还是以上面的图为例:
int main(){
Graph graph = create();
for (int c = 'A'; c <= 'D' ; ++c)
addVertex(graph, (char) c);
addEdge(graph, 0, 1); //A -> B
addEdge(graph, 1, 2); //B -> C
addEdge(graph, 2, 3); //C -> D
addEdge(graph, 3, 0); //D -> A
addEdge(graph, 2, 0); //C -> A
printGraph(graph);
}
我们来打印看看效果:
void printGraph(Graph graph){
for (int i = 0; i < graph->vertexCount; ++i) {
printf("%d | %c", i, graph->vertex[i].element);
Node node = graph->vertex[i].next;
while (node) {
printf(" -> %d", node->nextVertex);
node = node->next;
}
putchar('\n');
}
}
得到结果如下:

可以看到结果符合我们的预期。
不过虽然这样的方式看上去更加的简单高效,但是会给我们带来一些不必要的麻烦,比如上面创建的领接表,我们只能快速得到某个顶点指向了哪些顶点,也就是只能计算到顶点的出度,但是无法快速计算顶点的入度,只能将所有结点统计之后才能得到入度。所以说在表示有向图时,查找上并没有邻接矩阵来的方便。
为了解决这种问题,我们可以建立一个逆领接表,来表示所有指向当前顶点的顶点列表:
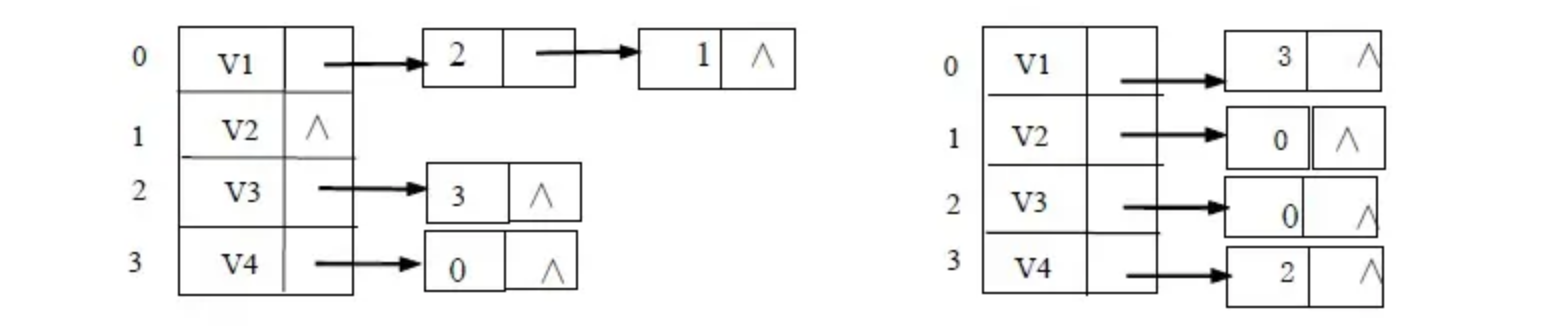
实际上就是反着来而已,通过建立这两个领接表,就能在一定程度上缓解不方便的情况。
图练习题:
-
在一个具有n个顶点的有向图中,若所有顶点的出度之和为s,则所有顶点的入度数之和为?
A. s B. s - 1 C. s + 1 D. 2s
有向图的所有出度实际上就是所有顶点连向其他顶点的边数,对于单个顶点来说,要么是自己指向别人(自己的出度,别人的入度),要么别人指向自己(别人的出度,自己的入度),这东西就是个相对的而已,而这些都可以一律看做出度,所以说所有顶点入度数之和就是所有顶点出度之和,所以选A
-
在一个具有n个顶点的无向完全图中,所含的边数为?
A. n B. n(n-1) C. n(n - 1)/2 D. n(n + 1)/2
首先回顾一下无向完全图的定义:在一个无向图中,任意两个顶点都有一条边相连,则称该图为无向完全图。既然任意两个顶点都有一个,那么每个结点都会有n-1条与其连接的边,所以说总数为
n \times (n-1)但是由于是无向图,没有方向之分,所以说需要去掉一半的数量,得到 $\frac {n \times (n-1)} {2}$,选择C -
若要把n个顶点连接为一个连通图,则至少需要几条边?
A. n B. n - 1 C. n + 1 D. 2n
连通图的定义是,每个顶点至少有一条到达其他顶点的路径,所以说我们只需要找一个最简单能够保证每个结点都有与其相连的就行了,也就是连成一根直线(或者是树)的情况,选择B
-
对于一个具有 n 个顶点和 e 条边的无向图,在其对应的邻接表中,所含边结点有多少个?
A. n B. ne C. e D. 2e
对于无向图,这结点个数等于边数的两倍,对于有向图,刚好等于边数,所以说选择 D
图的遍历
记得小时候每次去书店,都能看到迷宫书:

每次看到都想买一本,但是当时家里条件并不允许消费这么贵的书,所以都只能在书店多看几眼再回去。迷宫的解,实际上就是我们在一个复杂的地图中寻找一条能够从起点到达终点的路径。可以看到从起点开始,每到一个路口,可能都会出现多个分叉,可能有的分叉就会走进死胡同,有的分叉就会走到下一个路口。
那么我们人脑是怎么去寻找到正确的路径呢?
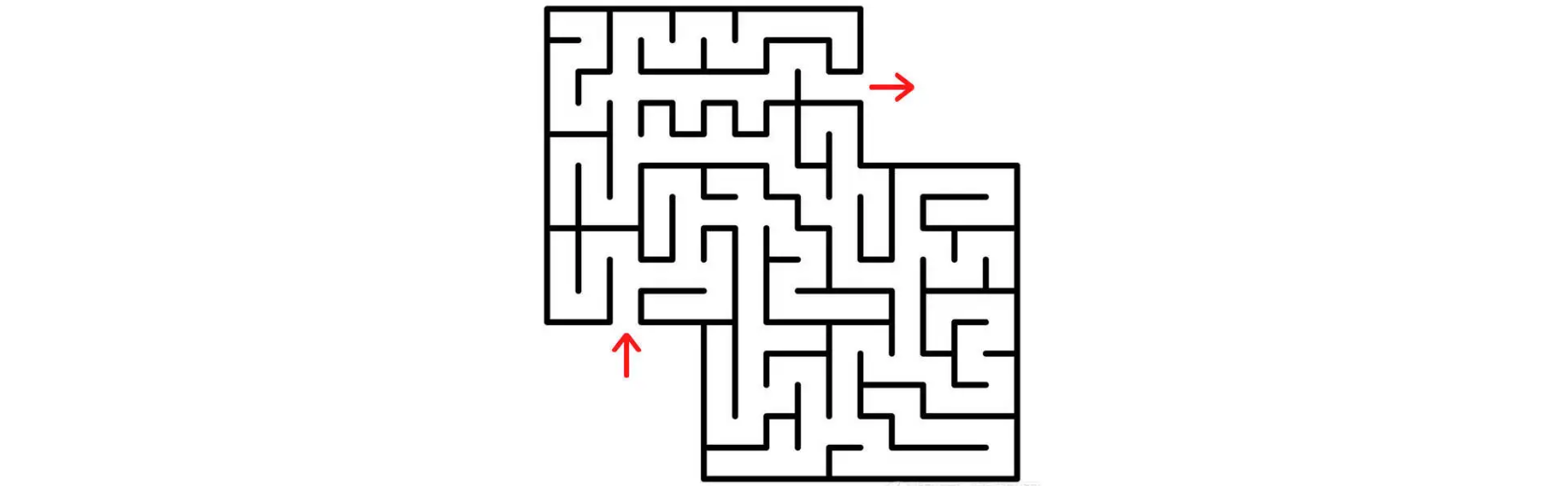
我们首先还是会从起点开始看,我们会尝试去走分叉路的每一个方向,如果遇到死胡同,那么我们就退回到上一个路口,再去尝试其他方向,直到能一直往下走为止。经过不断重复上述的操作,最后我们就肯定能够到达迷宫的出口了。
而图的搜索,实际上也是类似于迷宫这样的形式,我们需要从图的某一个顶点出发,去寻找到图中对应顶点的位置,这一部分,我们将对图的搜索算法进行讨论。
深度优先搜索(DFS)
我们之前在学习二叉树的过程中,讲解了树的前序遍历,各位回想一下,我们当时是如何在进行遍历的?
前序遍历就是勇往直前,直接走到底,然后再回去走其他的分支,而我们的图其实也可以像这样,我们可以一路向前,如果到了死胡同,那么就倒回去再走其他的方向,如果所有方向都走不通,继续再回到上一个路口(实际上就是我们人脑的思维)这样不断的寻找,肯定是可以找到的。
比如现在我们要从A开始寻找下图中的I:
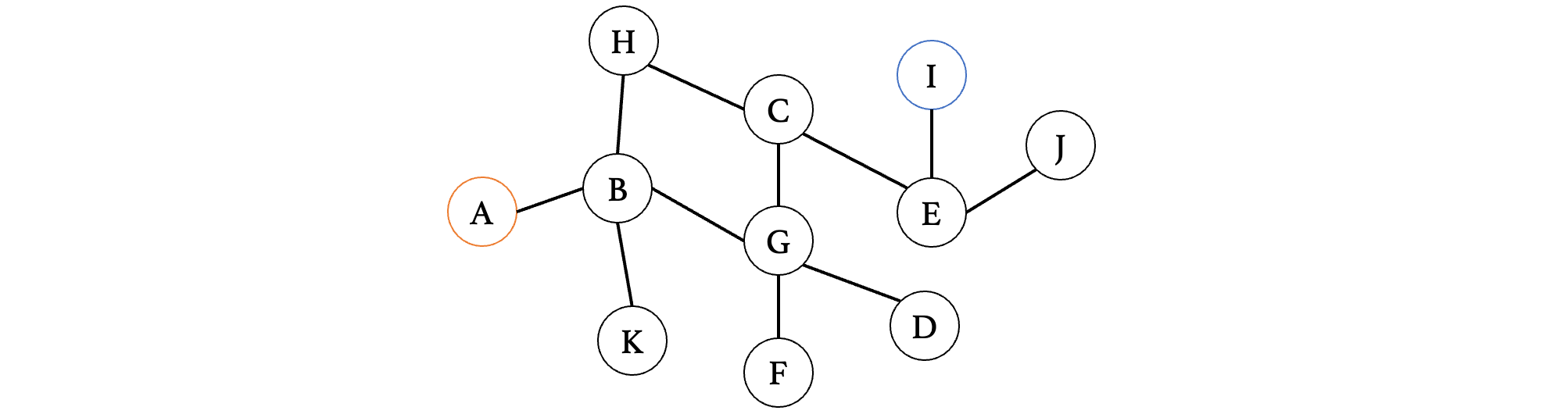
那么我们的路线可以是这样的:
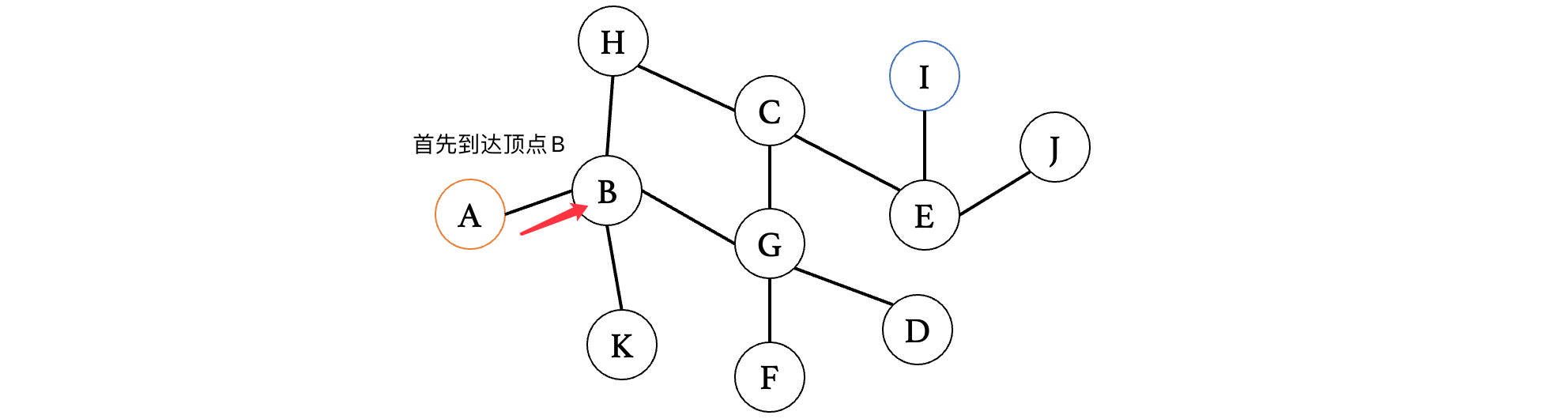
此时顶点B有三个方向,那么我们可以先随便选一个方向(当然,一般情况下为了规范,推荐按照字母排列顺序来走,这里为了演示,就随便走了)看看:
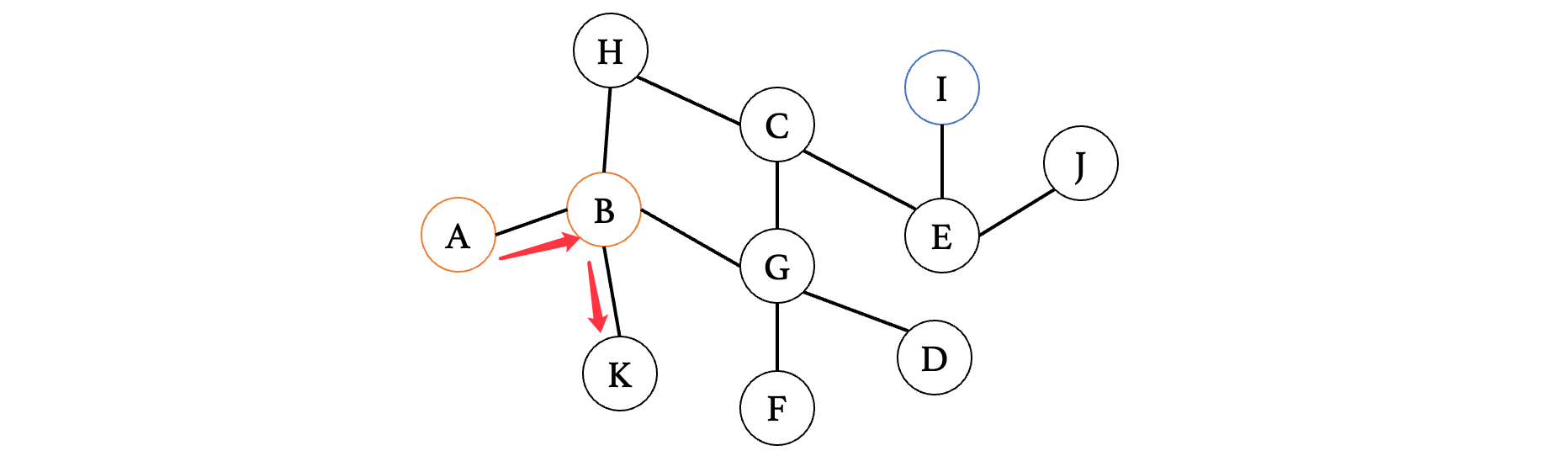
此时来到K,我们发现K已经是一个死胡同,没有其他路了,那么此时我们就需要回到上一个路口,继续去探索其他的路径:
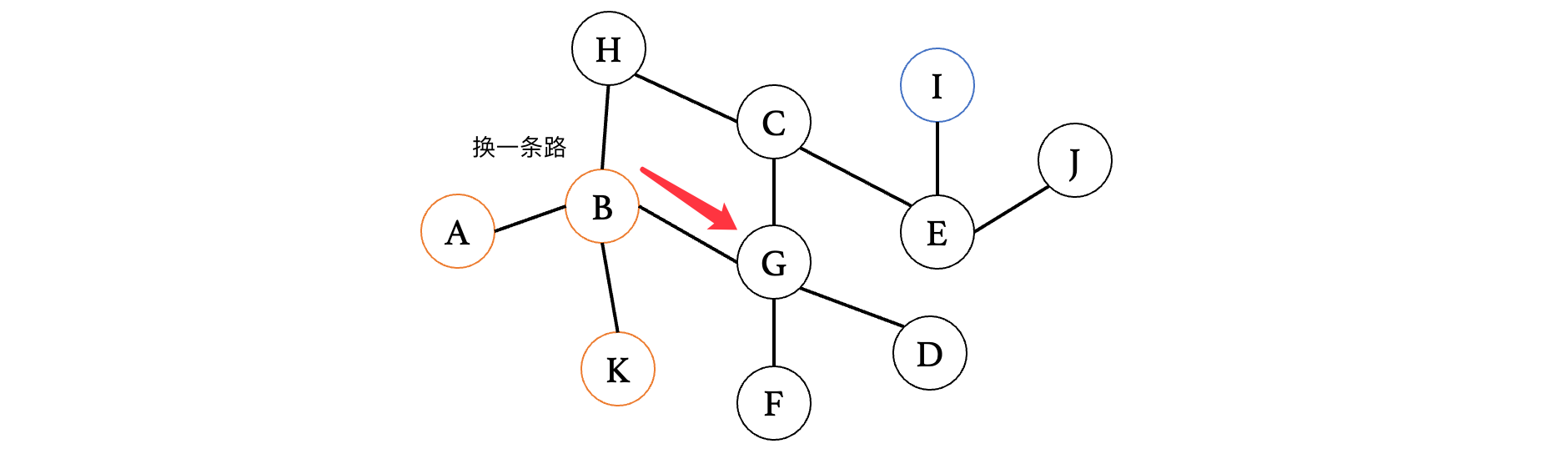
此时我们接着往下一个相邻的顶点G走,发现G有其他的分叉,那么我们就继续向前:
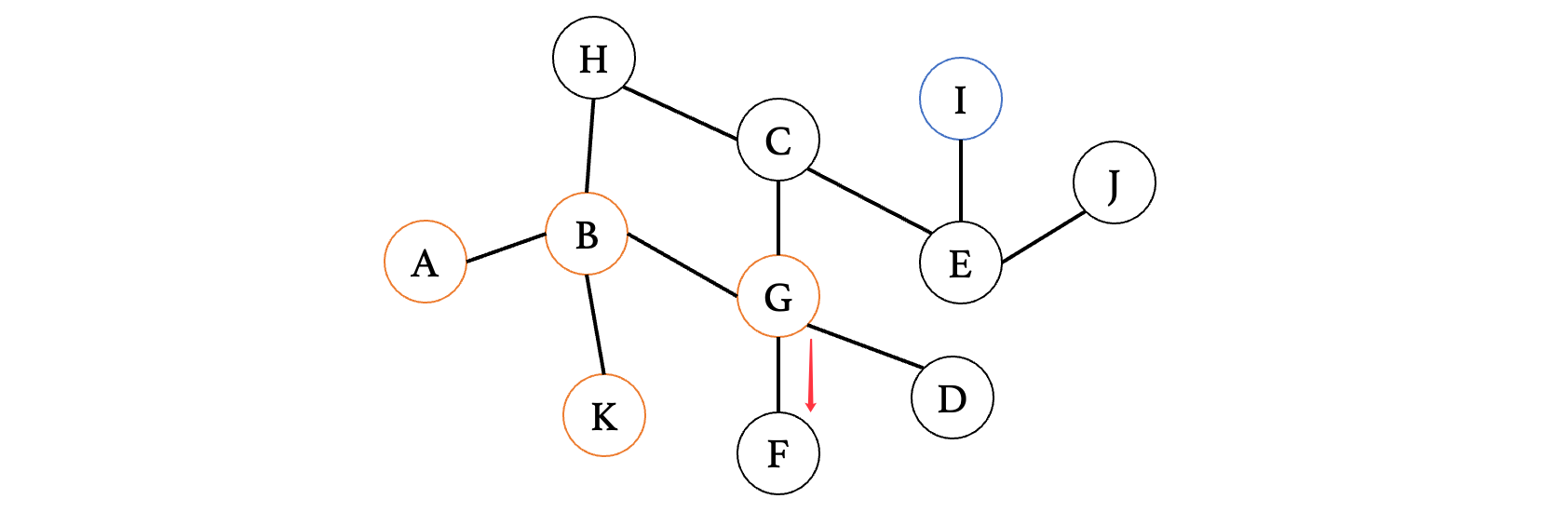
此时走到F发现又是死路,那么退回到G,走其他的方向:
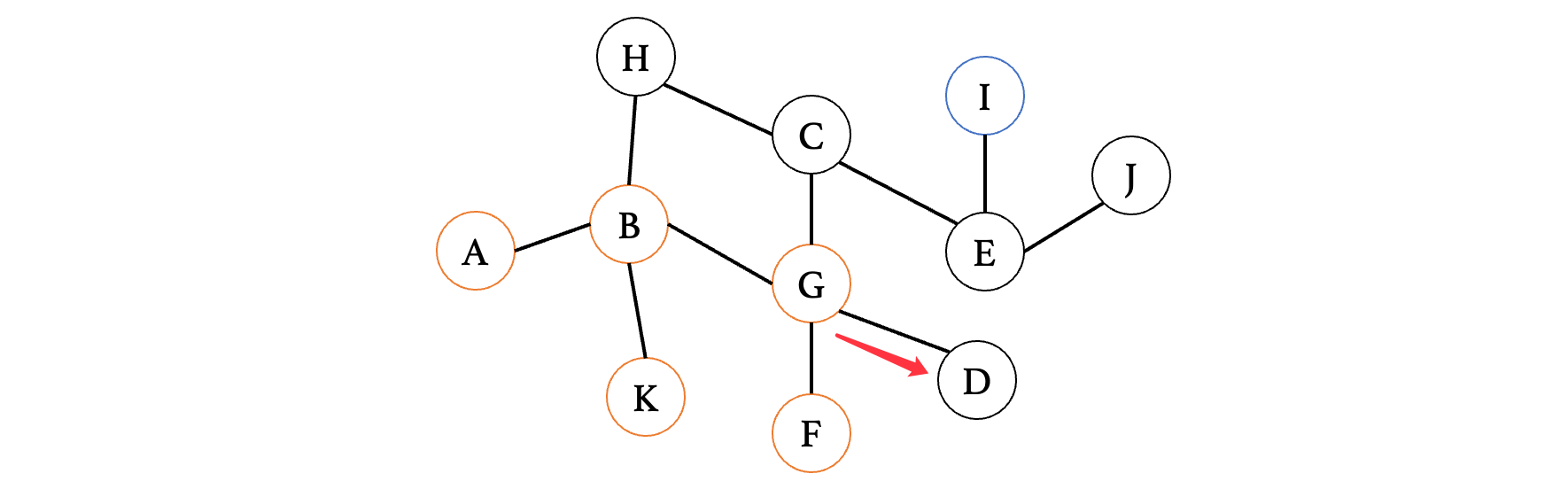
运气太垃了,又到死胡同了,同样的,回到G继续走其他方向:
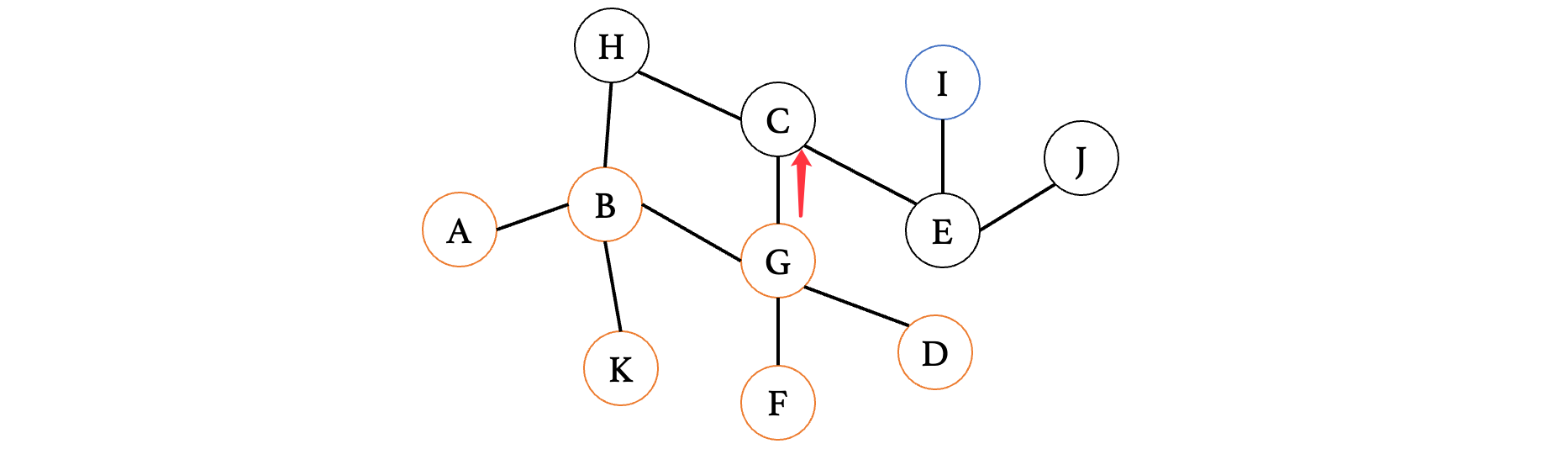
走到C之后,我们有其他的路,我们继续往后走:
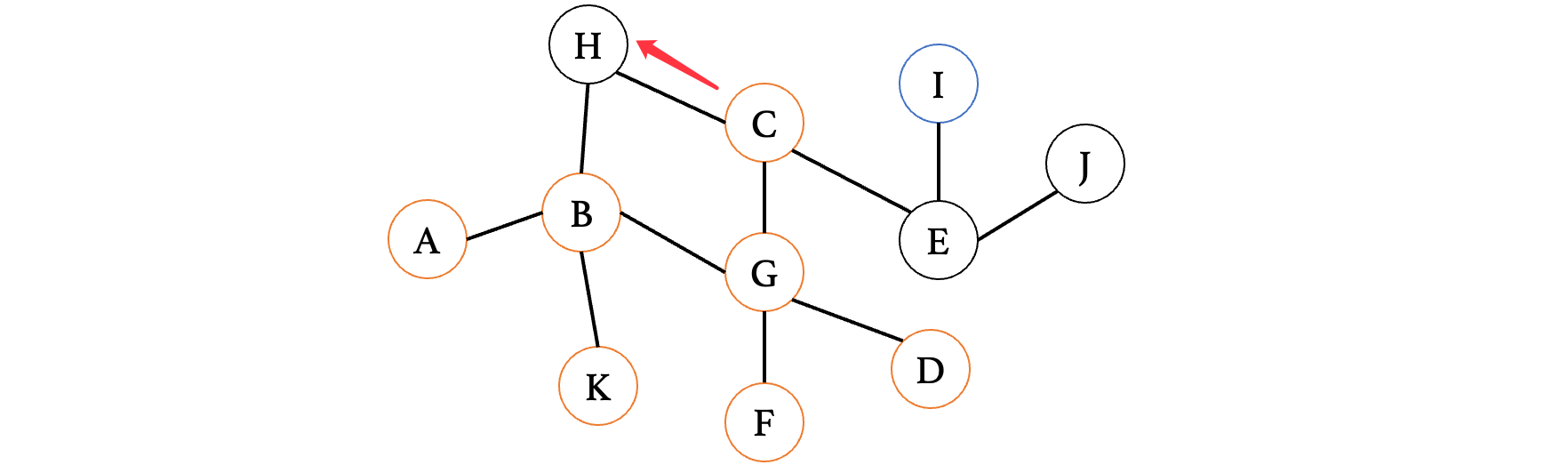
此时走到顶点H,发现H只有一条路,并且H再向前是已经走过的顶点B,那么此时不能再向前了,所以说直接退回到C,走另一边:
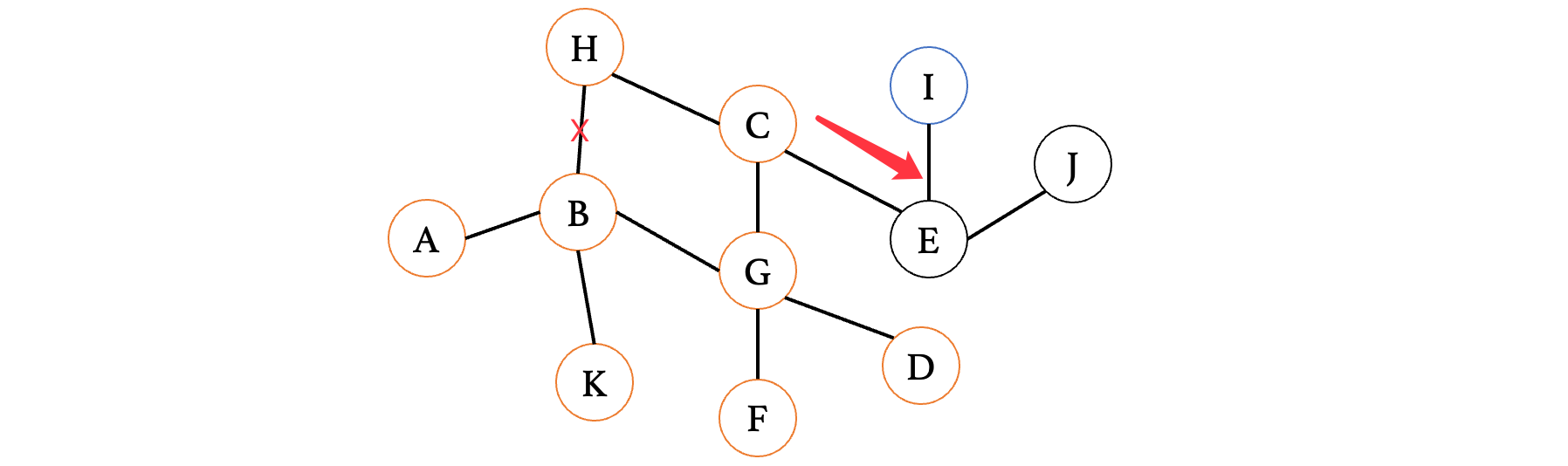
此时来到E,又有两条路,那么继续随便选一条走:
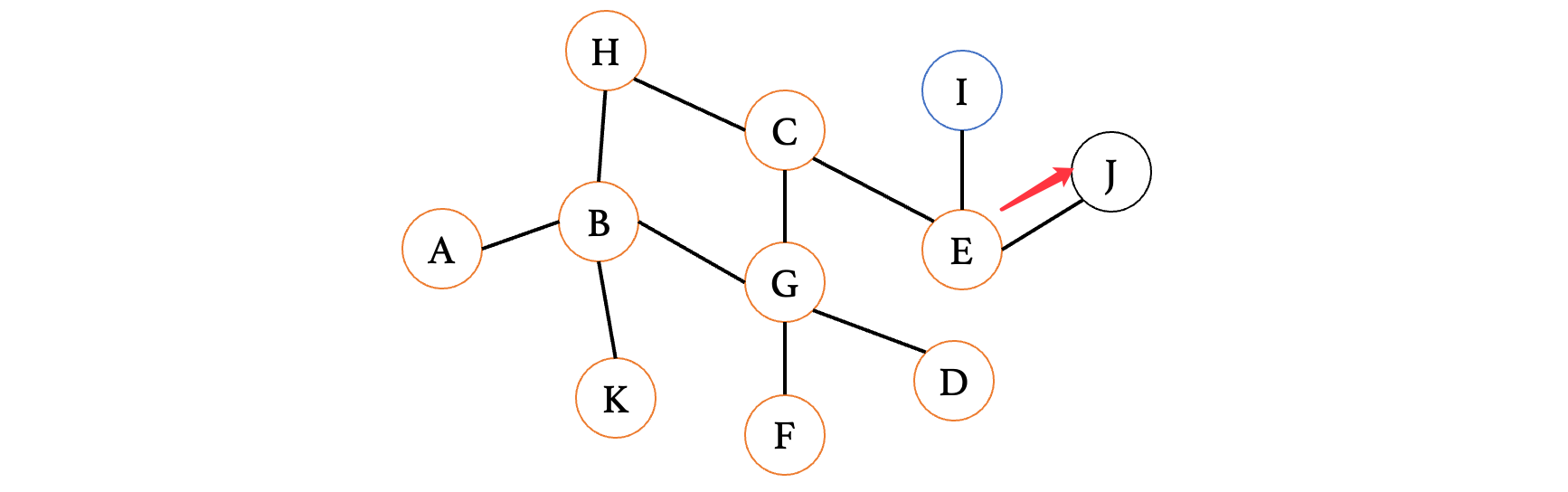
此时来到顶点J,发现又是死胡同,退回到E,继续走另一边:
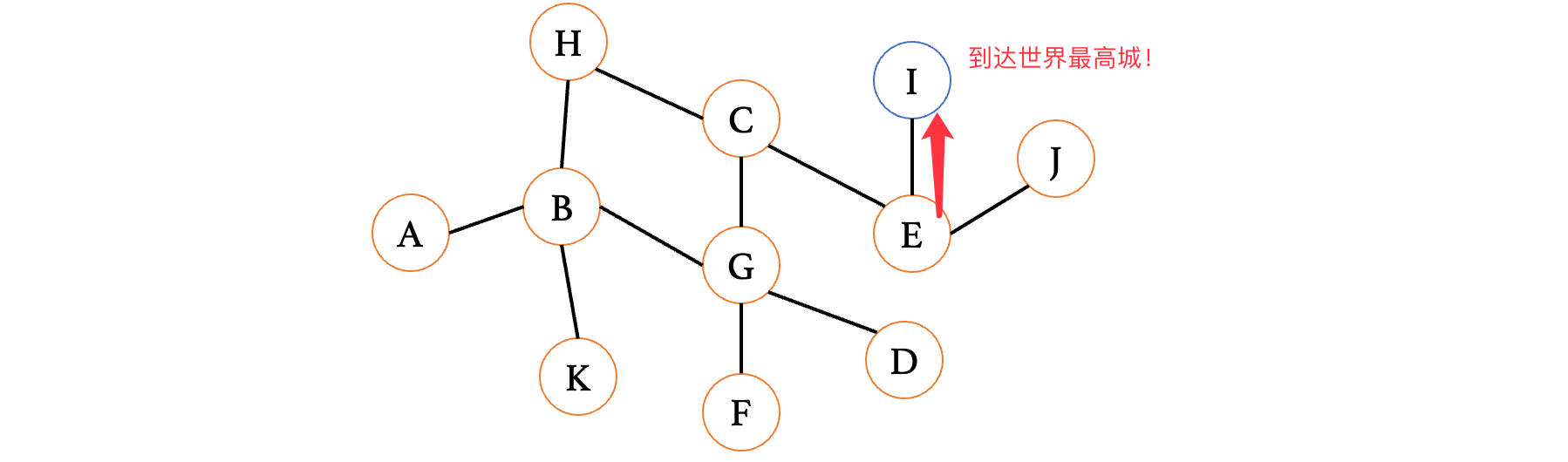
好了,经过了这么多试错,终于是找到了I顶点,这种方式就是深度优先搜索了。
那么我们就来打个代码玩玩吧,这里我们构建一个简单一点的图:
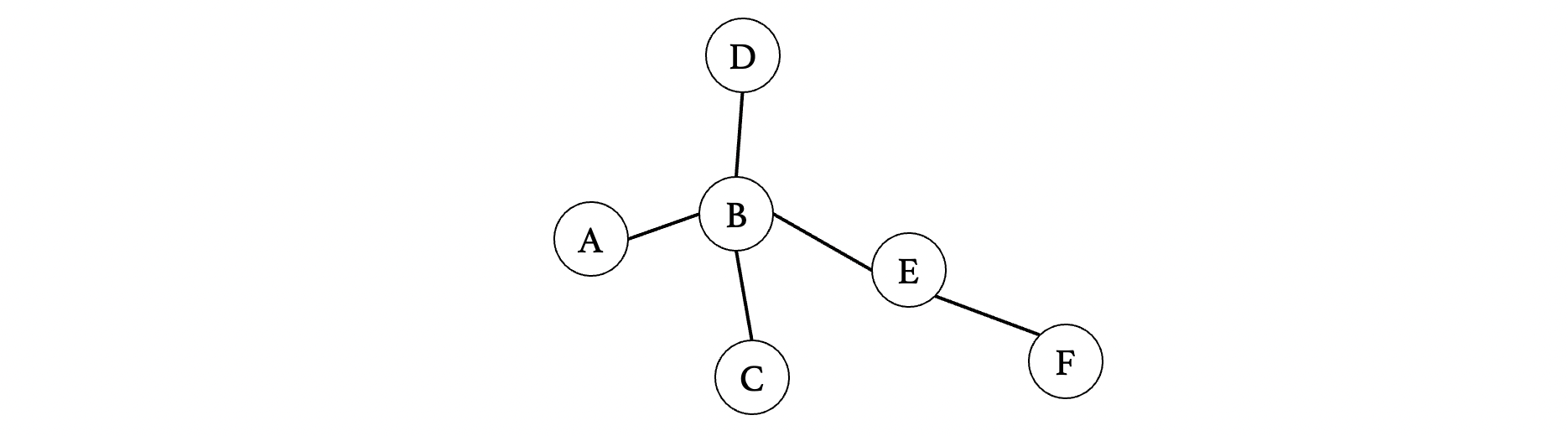
这里我们使用邻接表表示图,因为邻接表直接保存相邻顶点,所以说到达顶点时遍历相邻顶点会更快(能够到达 O(V + E) 线性阶)而如果使用邻接矩阵的话,我们得完整遍历整个二维数组,就比较费时间了(需要 O(V^2) 平方阶)。
比如现在我们想从A开始查找顶点F,首先先把图给建好(注意有6个顶点,记得容量写好):
int main(){
Graph graph = create();
for (int c = 'A'; c <= 'F' ; ++c)
addVertex(graph, (char) c);
addEdge(graph, 0, 1); //A -> B
addEdge(graph, 1, 2); //B -> C
addEdge(graph, 1, 3); //B -> D
addEdge(graph, 1, 4); //D -> E
addEdge(graph, 4, 5); //E -> F
printGraph(graph);
}

然后就是我们的深度优先搜索算法了:
/**
* 深度优先搜索算法
* @param graph 图
* @param startVertex 起点顶点下标
* @param targetVertex 目标顶点下标
* @param visited 已到达过的顶点数组
*/
void dfs(Graph graph, int startVertex, int targetVertex, int * visited){
}
我们先将深度优先遍历写出来:
/**
* 深度优先搜索算法(无向图和有向图都适用)
* @param graph 图
* @param startVertex 起点顶点下标
* @param targetVertex 目标顶点下标
* @param visited 已到达过的顶点数组
*/
void dfs(Graph graph, int startVertex, int targetVertex, int * visited) {
visited[startVertex] = 1; //走过之后一定记得mark一下
printf("%c -> ", graph->vertex[startVertex].element); //打印当前顶点值
Node node = graph->vertex[startVertex].next; //遍历当前顶点所有的分支
while (node) {
if(!visited[node->nextVertex]) //如果已经到过(有可能是走其他分支到过,或是回头路)那就不继续了
dfs(graph, node->nextVertex, targetVertex, visited); //没到过就继续往下走,这里将startVertex设定为对于分支的下一个顶点,按照同样的方式去寻找
node = node->next;
}
}
int main(){
...
int arr[graph->vertexCount];
for (int i = 0; i < graph->vertexCount; ++i) arr[i] = 0;
dfs(graph, 0, 5, arr);
}
深度优先遍历结果如下:

路线如下:
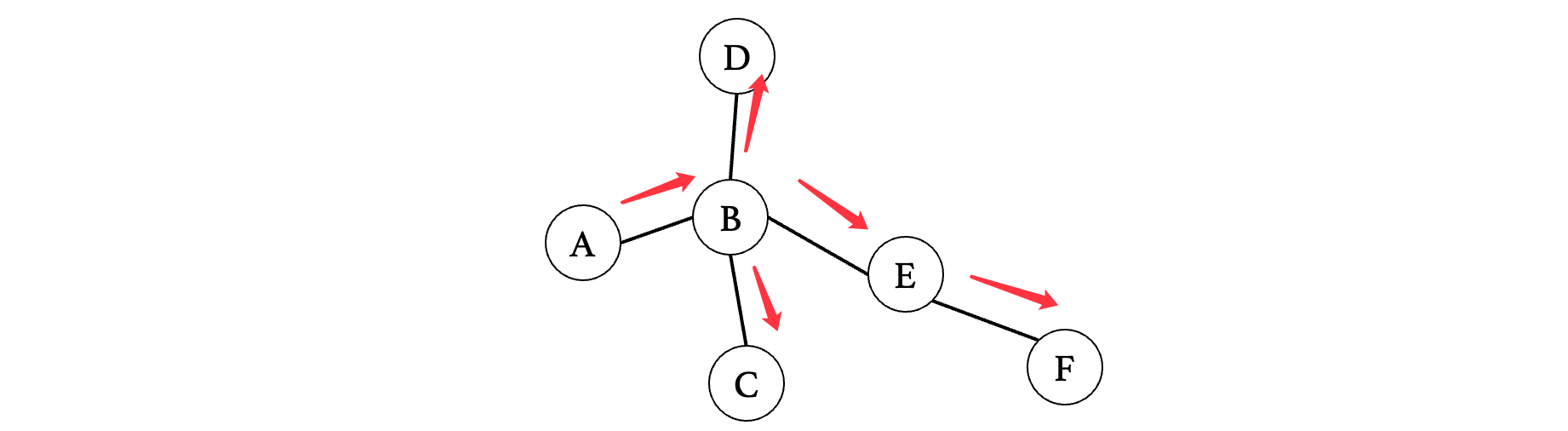
现在我们将需要查找的顶点进行判断:
/**
* 深度优先搜索
* @param graph 图
* @param startVertex 起点顶点下标
* @param targetVertex 目标顶点下标
* @param visited 已到达过的顶点数组
* @return 搜索结果,如果找到返回1,没找到返回0
*/
_Bool dfs(Graph graph, int startVertex, int targetVertex, int * visited) {
visited[startVertex] = 1;
printf("%c -> ", graph->vertex[startVertex].element);
if(startVertex == targetVertex) return 1; //如果当前顶点就是要找的顶点,直接返回
Node node = graph->vertex[startVertex].next;
while (node) {
if(!visited[node->nextVertex])
if(dfs(graph, node->nextVertex, targetVertex, visited)) //如果查找成功,直接返回1,不用再看其他分支了
return 1;
node = node->next;
}
return 0; //while结束那肯定是没找到了,直接返回0
}
int main(){
...
int arr[graph->vertexCount];
for (int i = 0; i < graph->vertexCount; ++i) arr[i] = 0;
printf("\n%d", dfs(graph, 0, 5, arr));
}
得到结果如下:

再来找一下顶点D呢:

可以看到到D之后就停止了,因为已经找到了。那么要是去寻找一个没有连接到图中的结点呢?

可以看到整个图按照深度优先遍历找完了都没找到。
广度优先搜索(BFS)
前面我们介绍了深度优先搜索,我们接着来看另一种方案。还记得我们在前面二叉树中学习的层序遍历吗?

层序遍历实际上是优先将每一层进行遍历,而不是像前序遍历那样勇往直前,而图的搜索其实也可以采用这种方案,我们可以先探索顶点所有的分支,然后再依次去看这些分支的所有分支:
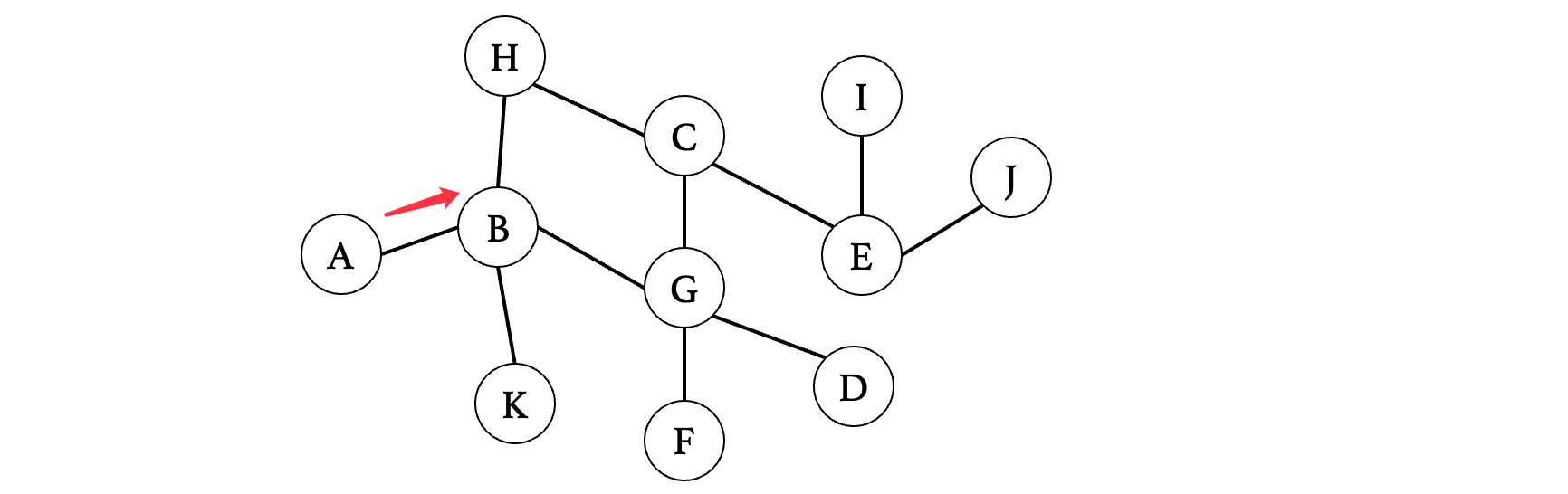
首先咱还是从A来到B,此时B有三条分叉路,我们依次访问这三条路的各个顶点:
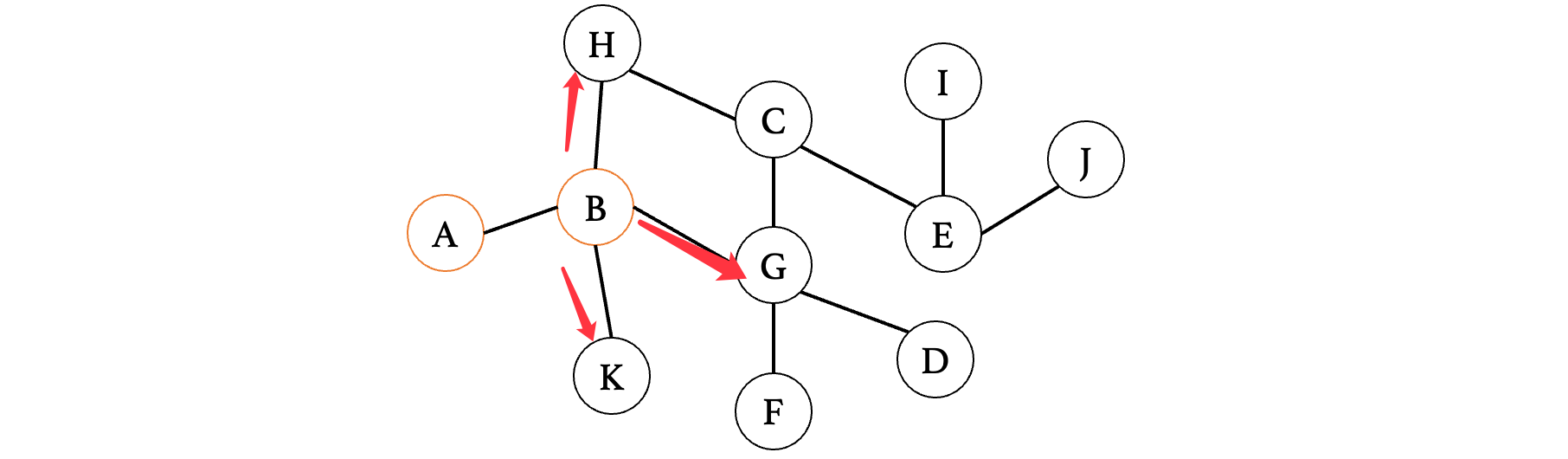
我们先记录一下这三个顶点,同样需要使用队列来完成:H、G、K
注意访问之后不要再继续向下了,接着我们从这三个里面的第一个顶点H开始,按照同样的方法继续:
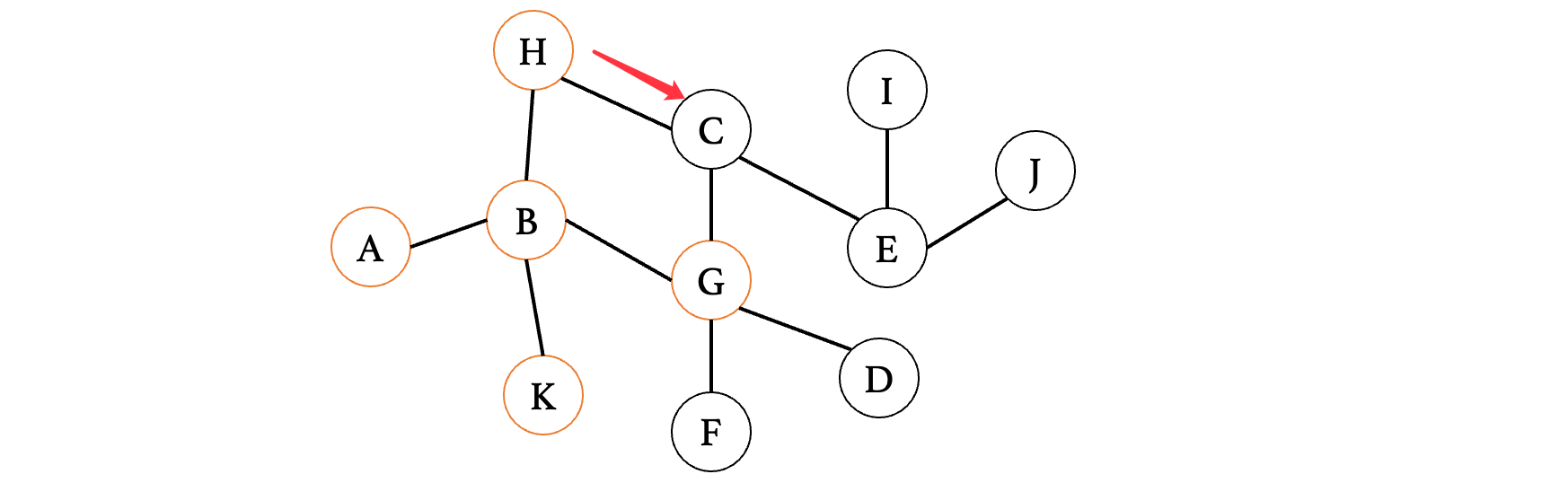
此时因为只有一个分支,所以说找到C,继续记录,将C也添加进去:G、K、C
注意此时需要回去,继续看之前三个顶点的第二个顶点G:
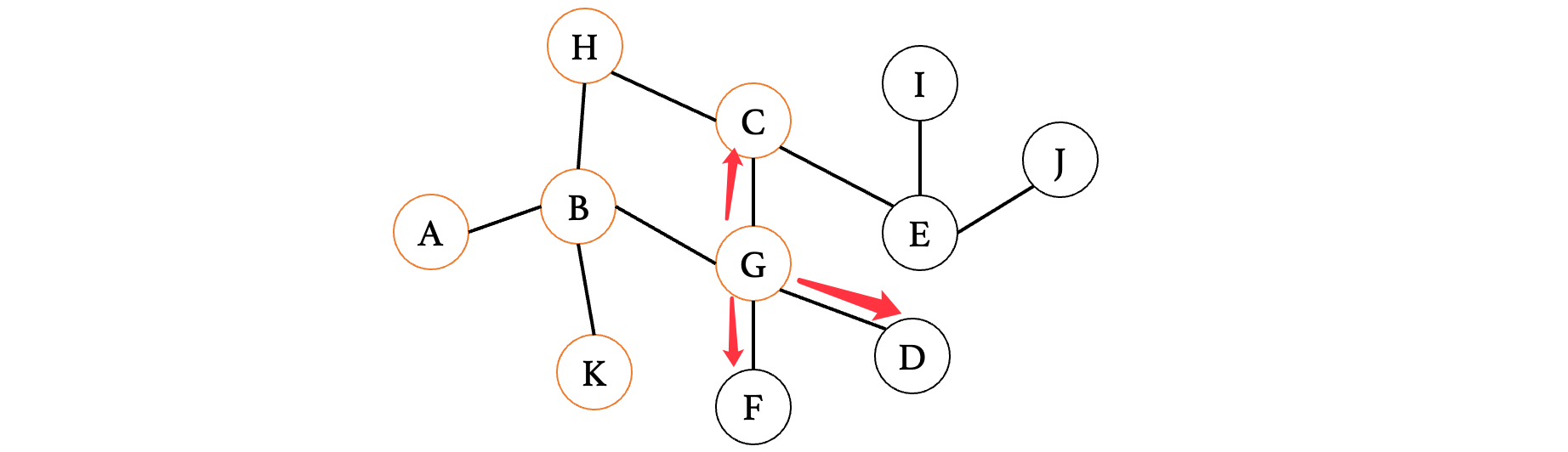
此时C已经看过了,接着就找到了F和D,也是记录一下:K、C、F、D
然后,我们继续看之前三个结点的最后一个:
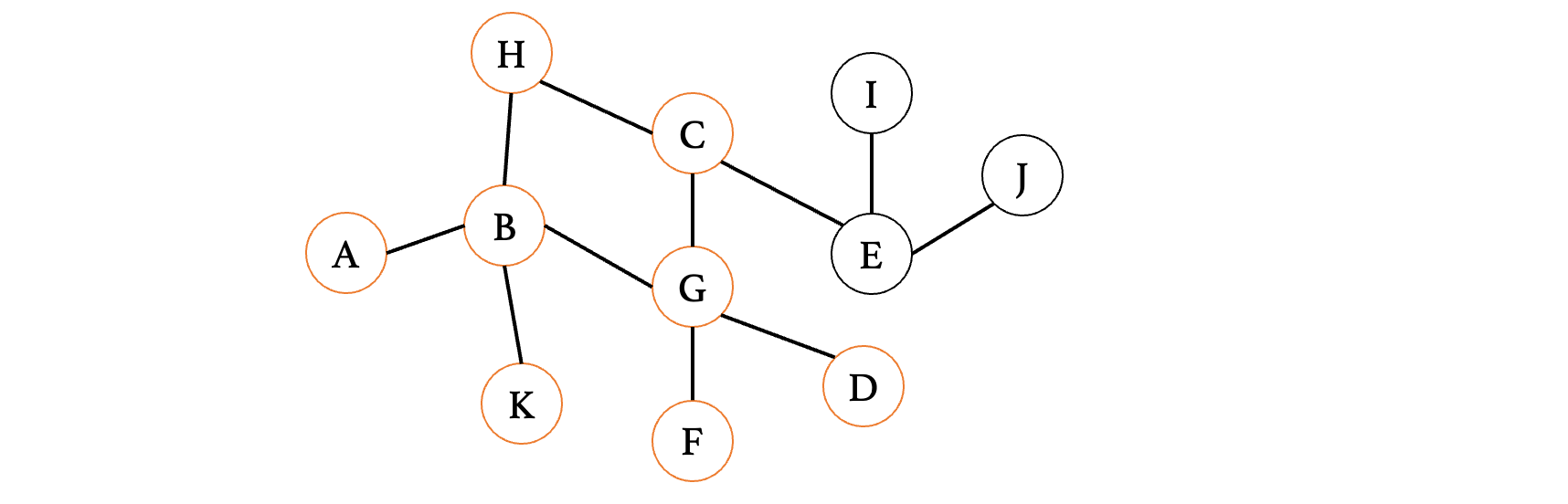
此时K已经是死胡同了,那么就结束,然后继续看下一个C:
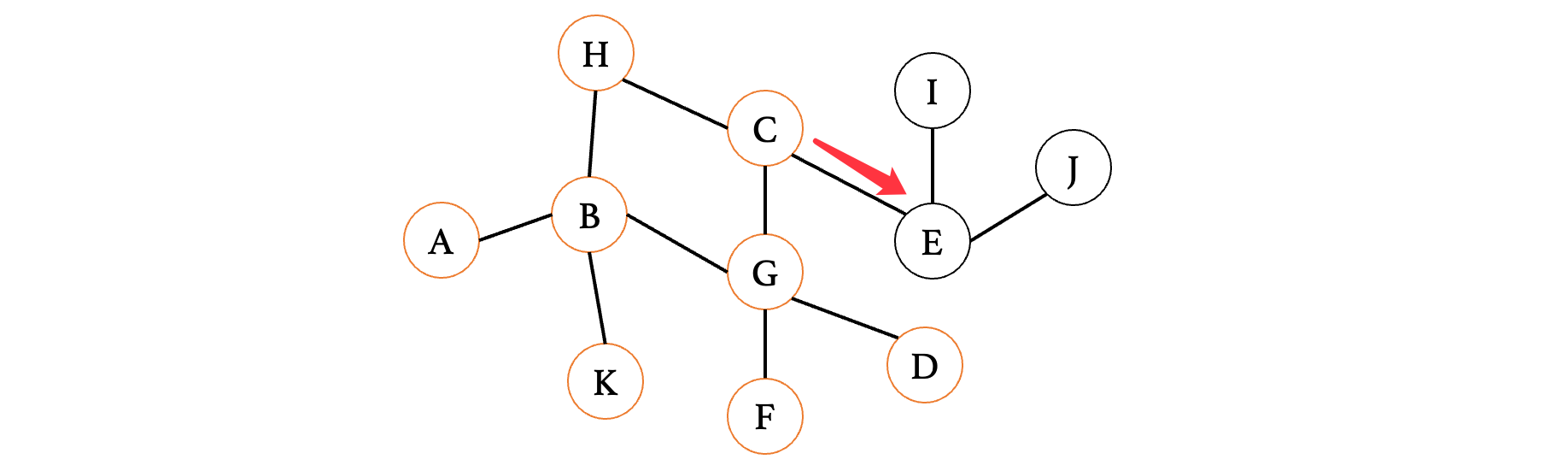
此时继续将E给记录进去:F、D、E,接着看D和F,也没有后续了,那么最后就只有E了:
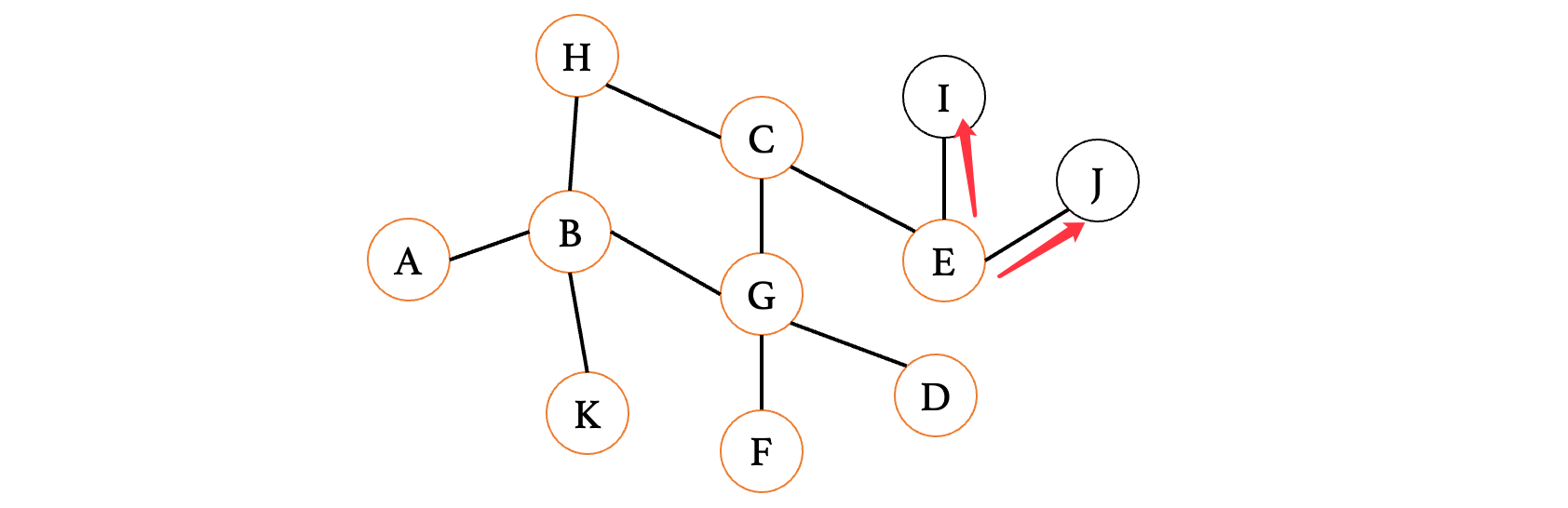
成功找到目标I顶点,实际上广度优先遍历就是尽可能地扩展范围,多去探索广阔的土地,而不是死拽着一根不放,就像爱情,实在得不到就算了吧,她至始至终就没爱过你,不要继续在她身上浪费感情了,多去结交新的朋友,相信你会遇到更好的。
那么按照这个思路,我们就来尝试代码实现一下,首先把队列搬过来:
typedef int T; //这里将顶点下标作为元素
struct QueueNode {
T element;
struct QueueNode * next;
};
typedef struct QueueNode * QNode;
struct Queue{
QNode front, rear;
};
typedef struct Queue * LinkedQueue;
_Bool initQueue(LinkedQueue queue){
QNode node = malloc(sizeof(struct QueueNode));
if(node == NULL) return 0;
queue->front = queue->rear = node;
return 1;
}
_Bool offerQueue(LinkedQueue queue, T element){
QNode node = malloc(sizeof(struct QueueNode));
if(node == NULL) return 0;
node->element = element;
queue->rear->next = node;
queue->rear = node;
return 1;
}
_Bool isEmpty(LinkedQueue queue){
return queue->front == queue->rear;
}
T pollQueue(LinkedQueue queue){
T e = queue->front->next->element;
QNode node = queue->front->next;
queue->front->next = queue->front->next->next;
if(queue->rear == node) queue->rear = queue->front;
free(node);
return e;
}
我们还是以上面的图为例:
/**
* 广度优先遍历
* @param graph 图
* @param startVertex 起点顶点下标
* @param targetVertex 目标顶点下标
* @param visited 已到达过的顶点数组
* @param queue 辅助队列
*/
void bfs(Graph graph, int startVertex, int targetVertex, int * visited, LinkedQueue queue) {
offerQueue(queue, startVertex); //首先把起始位置顶点丢进去
visited[startVertex] = 1; //起始位置设置为已走过
while (!isEmpty(queue)) {
int next = pollQueue(queue);
printf("%c -> ", graph->vertex[next].element); //从队列中取出下一个顶点,打印
Node node = graph->vertex[next].next; //同样的,把每一个分支都遍历一下
while (node) {
if(!visited[node->nextVertex]) { //如果没有走过,那么就直接入队
offerQueue(queue, node->nextVertex);
visited[node->nextVertex] = 1; //入队时就需要设定为1了
}
node = node->next;
}
}
}
我们来测试一下吧:
int main(){
...
int arr[graph->vertexCount];
struct Queue queue;
initQueue(&queue);
for (int i = 0; i < graph->vertexCount; ++i) arr[i] = 0;
bfs(graph, 0, 5, arr, &queue);
}
成功得到结果:

如果要指定查找的话,就更简单了:
_Bool bfs(Graph graph, int startVertex, int targetVertex, int * visited, LinkedQueue queue) {
offerQueue(queue, startVertex);
visited[startVertex] = 1;
while (!isEmpty(queue)) {
int next = pollQueue(queue);
printf("%c -> ", graph->vertex[next].element);
Node node = graph->vertex[next].next;
while (node) {
if(node->nextVertex == targetVertex) return 1; //如果就是我们要找的,直接返回1
if(!visited[node->nextVertex]) {
offerQueue(queue, node->nextVertex);
visited[node->nextVertex] = 1;
}
node = node->next;
}
}
return 0; //找完了还没有,那就返回0
}
这样,我们就实现了图的广度优先搜索。
图练习题:
-
若一个图的边集为:{(A, B),(A, C),(B, D),(C, F),(D, E),(D, F)},对该图进行深度优先搜索,得到的顶点序列可能是:
A. ABCFDE B. ACFDEB C. ABDCFE D. ABDFEC
这种题直接把图画出来,因为边集是圆括号,说是肯定是一个无向图,图先画出来再说:
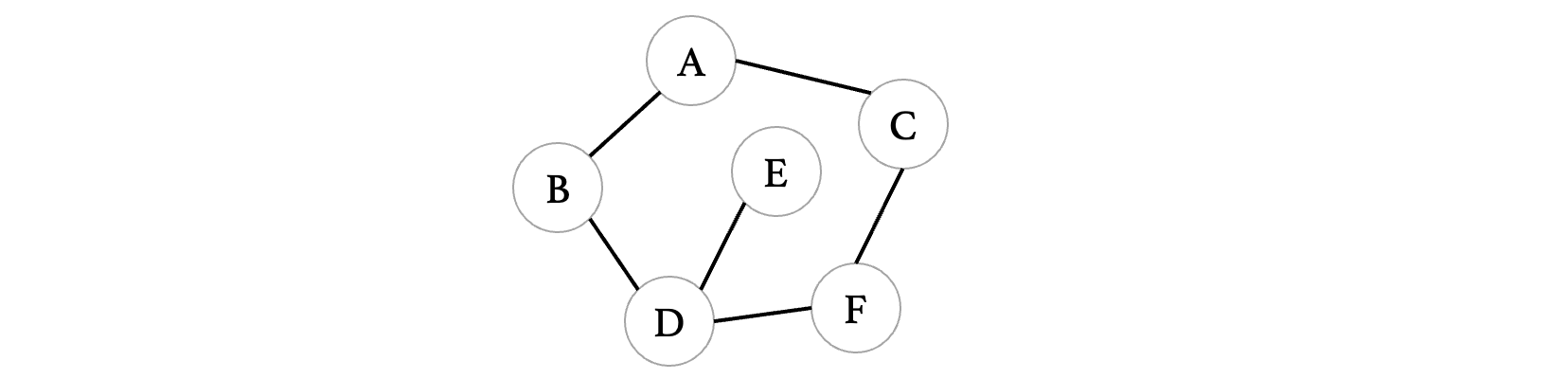
因为这四个选项都是A开始的,所以说我们从A开始看,因为A连接了B和C,所以说A后面紧跟B或是C都可以,接着往下看,先看走B的情况,因为B只连接了一个D,所以说选项A直接排除,接着往下看,D链接了E和F,所以说选项C直接排除,此时只有选项D了,我们接着往后看,此时我们走F,紧接着的只有C,D也不满足,所以选择B(当然你怕不稳的话把B选项也推出来就行了)
-
若一个图的边集为:{(A, B),(A, C),(B, D),(C, F),(D, E),(D, F)},对该图进行广度优先搜索,得到的顶点序列可能是:
A. ABCDEF B. ABCFDE C. ABDCEF D. ACBFDE
跟上面是同样的思路,只要各位小伙伴听懂了BFS和DFS的思路,肯定没问题的,选择 D
-
如下图所示的无向连通图,从顶点A开始对该图进行广度优先遍历,得到的顶点序列可能是:
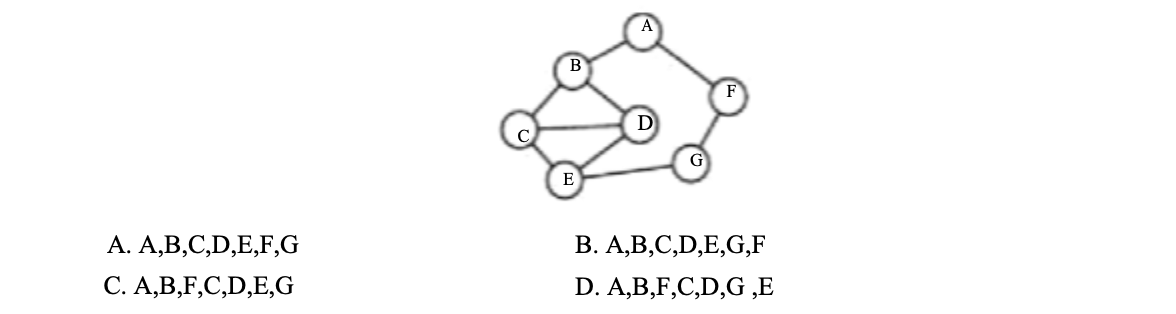
同样的思路,选择D
图应用
前面我们介绍了图的相关性质,以及图的遍历方式,这一部分我们接着来看图的相关应用。
生成树和最小生成树
在开始讲解最小生成树之前,我们先来回顾一下之前讲解的连通分量。
- 对于无向图来说,如果图中任意两点都是连通的,那么我们就称这个图为连通图。
- 对于有向图来说,如果图中任意顶点A和B,既有从A到B的路径,也有B到A的路径,则称该有向图是强连通图。
而连通分量则要求是某个图的子图(子图可以是只包原图含部分顶点和边的图,也可以就是原图本身,因为定义只是子集,不是真子集),并且子图也要是连通的才可以,还有一个重要条件是必须拥有极大顶点数(能够保证图连通的且包含原图最大的顶点数)并且包含所有依附于这些顶点的边(这个极大更偏向于顶点数的极大),我们就称这个子图为极大连通子图。
- 无向图的极大连通子图称为连通分量。
- 有向图的极大强连通子图称为强连通分量。
比如下面的有向图,这个图本身并不是连通的:

其中图1和图2都满足上述条件,都是强连通分量,本身就是连通并且已经到达最大的顶点数和边数了(只要再加入其他的顶点和边就会导致不连通)但是图3并不是子图(A到B的边缺失)并且不是强连通的,所以说不是强连通分量。
又比如下面这个无向图,这个图本身也是不连通的:
其中图1和图3都满足条件,都是连通分量,但是图2并没有到达最大的顶点数和边数,所以说不是连通分量。
当然上面都是原图不连通的情况,如果原图就是一个连通图,包含其所有顶点和边的子图就已经满足条件了,所以其本身就是一个连通分量;同样的,如果原图就是一个强连通图,那么其本身就是一个强连通分量。
总结如下:
- 如果原图本身不连通,那么其连通分量(强连通分量)不止一个。
- 如果原图本身连通,那么其连通分量(强连通分量)就是其本身。
极大连通子图我们回顾完了,那么我们接着来讨论一下极小连通子图。这里的极小主要是说的边数的极小,首先依然要是原图的子图并且是连通的,但是此时要求具有最大的顶点数和最小的边数,也就是说再去掉任意一条边会导致图不连通(直接理解为极大连通子图尽可能去掉能去掉的边就行了)
针对于极小连通子图,我们一般只讨论无向图(对于有向图,不存在极小强连通子图的说法,因为主要是讨论生成树)我们依然将原图就是连通图和原图不是连通图分开分析,首先是原图本身就是连通图的情况:
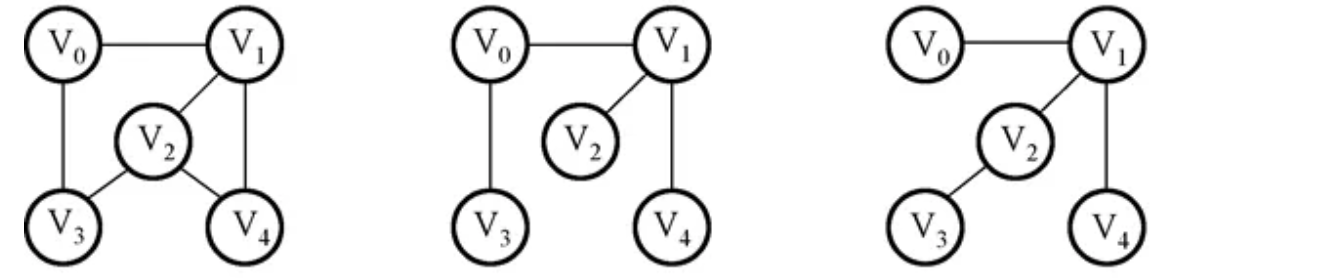
原图本身就是连通图,那么其极大连通子图就是其本身,此时我们需要尽可能去掉那些“不必要”的边,依然能够保证其是连通的,也就是极小连通子图。可以看到右边两幅图,跟左边这幅图包含了同样的顶点数量,但是边数被去掉了一些,并且如果再继续去掉任意一条边的话,那么就会导致不连通,所以说左边两幅图都是右边这幅图的极小连通图(当然,就像上面这样,可能会出现多种方案,极小连通图不唯一)
我们发现,无论是去掉哪些边的情况,到最后一定是只留下 N-1 条边(其中N是顶点数)每个顶点有且仅有一条路径相连,也就是包含原图全部N个顶点的极小连通子图,我们一般称其为:生成树,为什么叫生成树呢,因为结点数和边数正好满足树的定义(且不存在回路的情况),我们可以将其调整为一棵树:
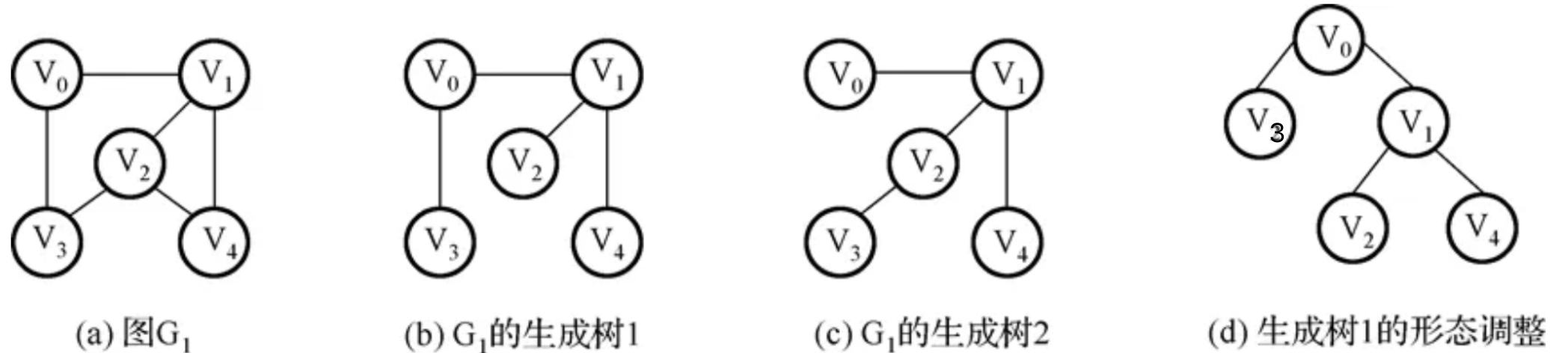
当然,这是原图本身就连通的情况,如果原图本身不连通的话,那么就会出现多个连通分量,此时就会得到一片生成森林,森林中的树的数量就是其连通分量的数量。
那么我们在程序中要怎么才能得到一个有向图的生成树呢?我们可以使用前面讲解的两种图的遍历方式来进行生成,我们以下图为例,这是一个普通的无向连通图:

我们如果按照深度优先遍历的方式,从G开始,那么就会得到下面的顺序:
按照顺序我们就可以得到一棵生成树:
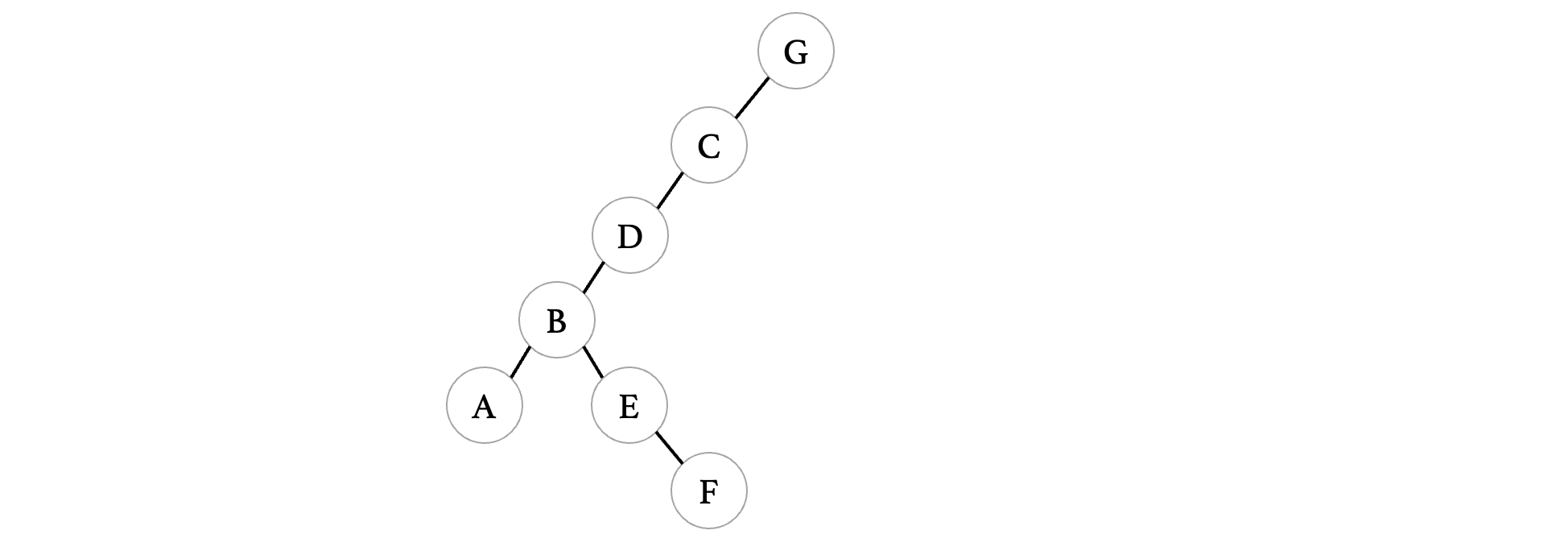
虽然看着很奇怪,但是按照我们的顺序,得到的树就是这样的,可以发现,因为我们的深度优先搜索不会去走那些回头路,相当于直接把哪些导致回路和多余的边给去掉了,最后遍历得到的结果就是一颗生成树了。
同样的,我们来看看如果是按照广度优先遍历的方式,又会得到什么结果呢?
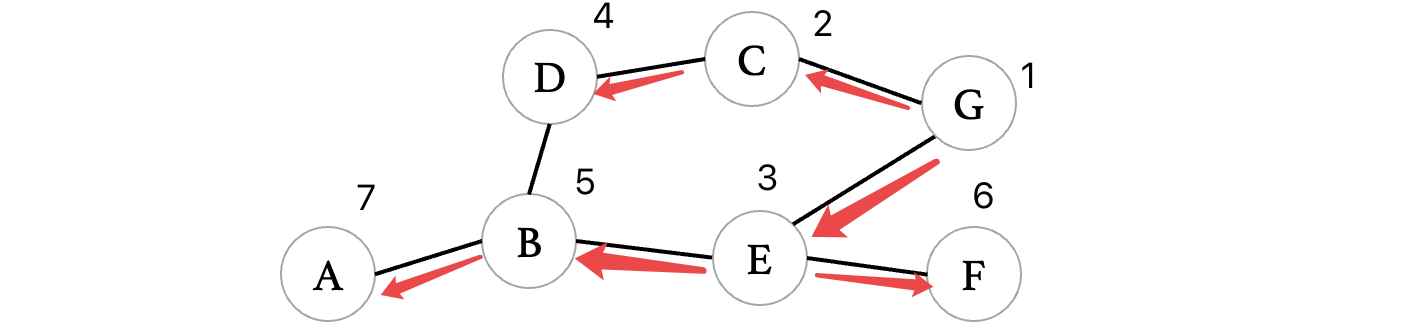
最后得到的生成树为:
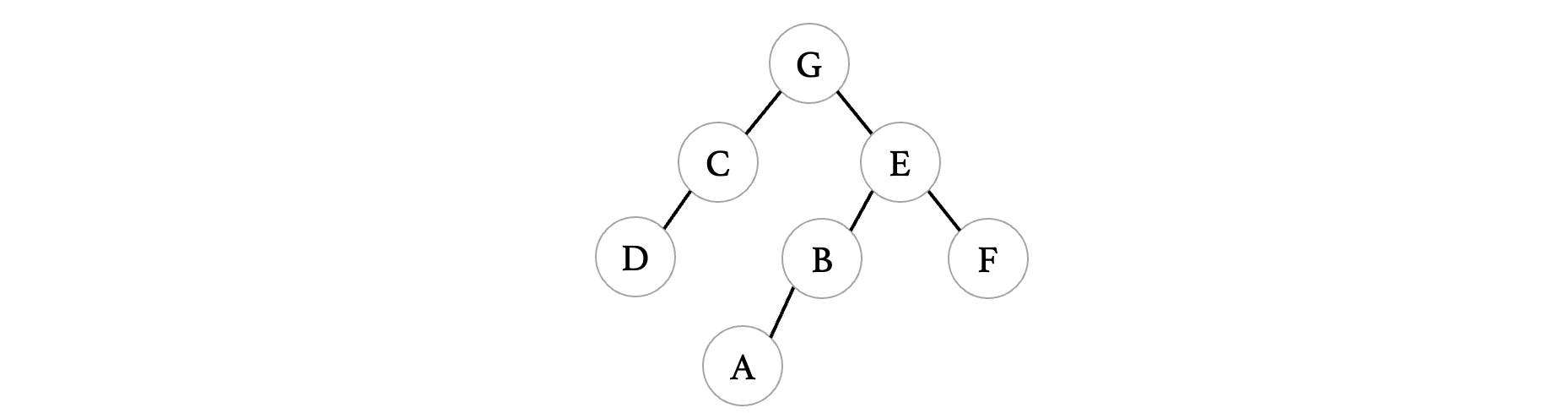
实际上我们发现,在广度优先遍历下得到的生成树,也是按照每一层在进行排列的,非常清晰。当然,因为深度优先遍历和广度优先遍历本身的顺序就不是唯一的,所以最后得到的生成树也不是唯一的。
生成树讨论完成之后,我们接着来讨论一下最小生成树,那么这个最小指的是什么最小呢?如果我们给一个无向图的边都加上权值(网图)现在要求生成树边的权值总和最小,我们就称这棵树为最小生成树(注意最小生成树不唯一,因为有可能出现多种方案都是最小的情况)比如下面的就是最后得到的最小生成树了:
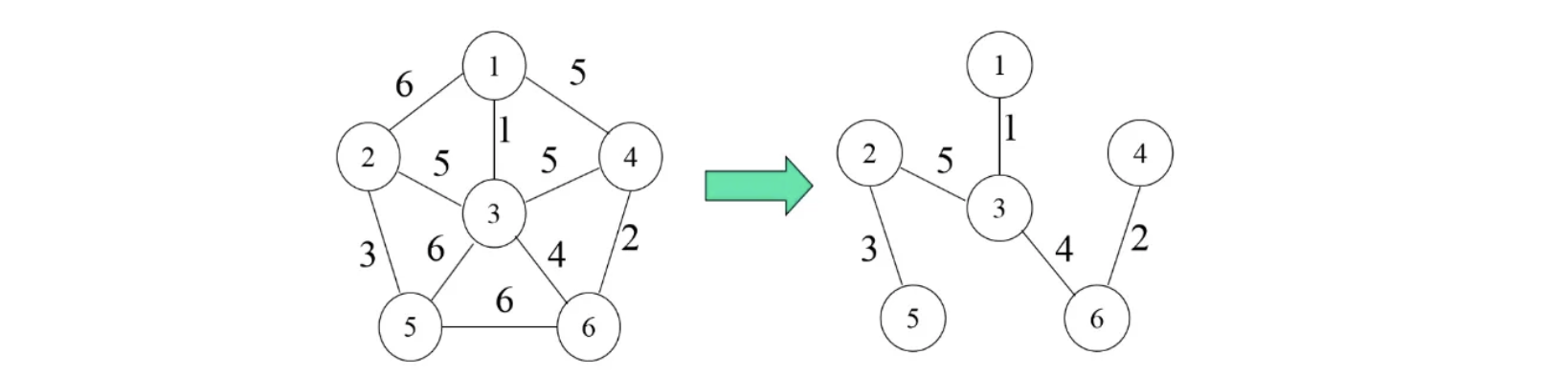
构建最小生成树有两种算法,一种是**普利姆(Prim)算法,还有一种是克鲁斯卡尔(Kruskal)**算法,我们先来讨论第一种:
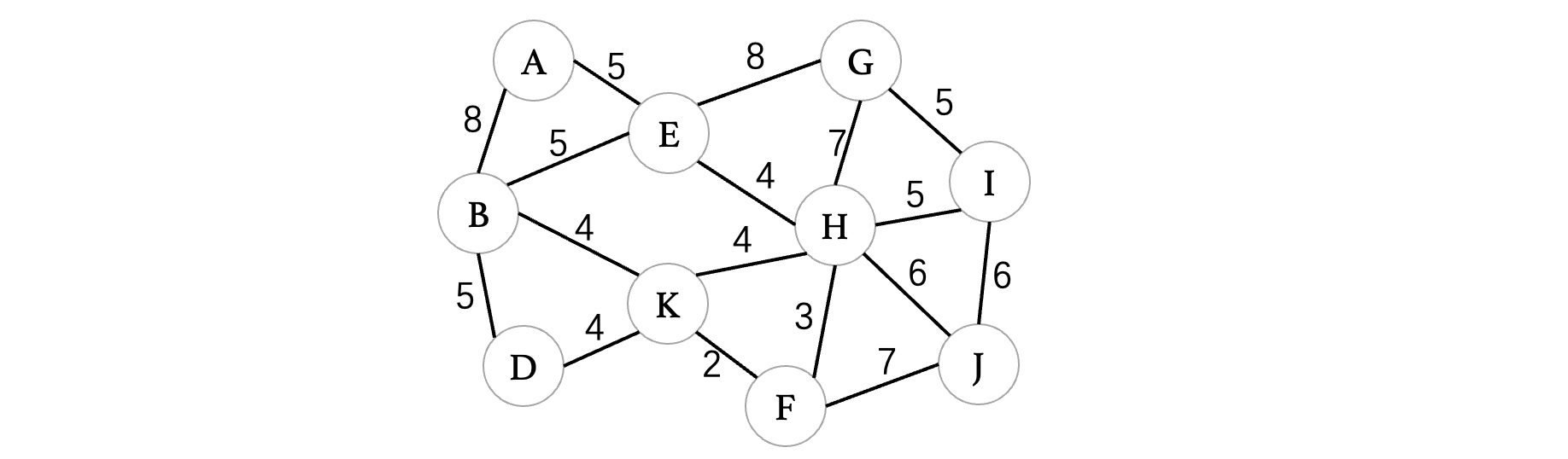
我们以下图为例:
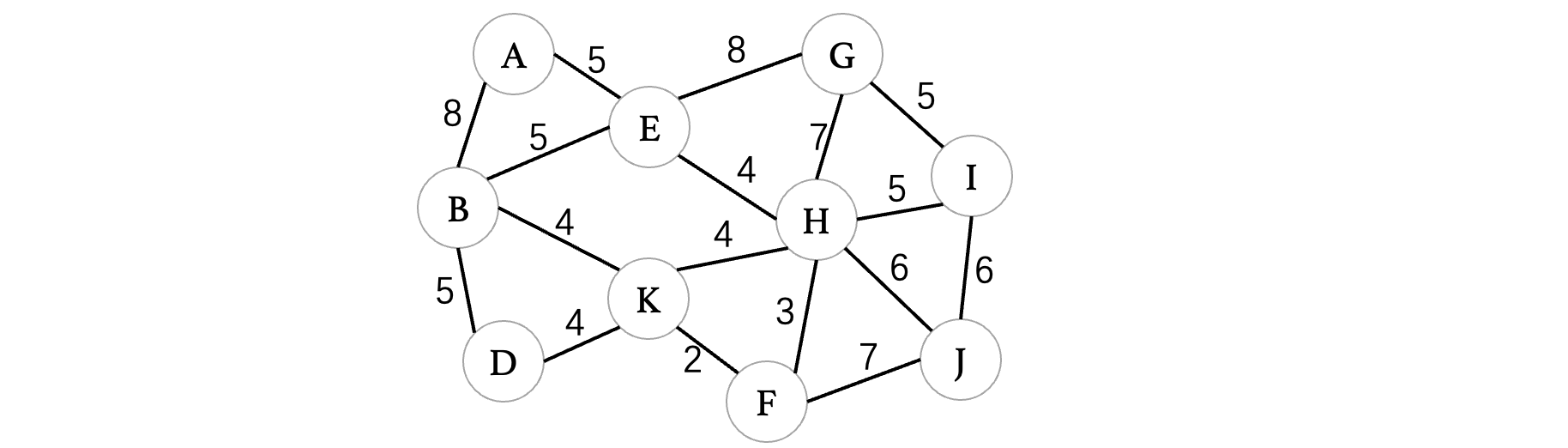
普利姆算法的核心就是从任意一个顶点开始,不断成长为一棵树,每次都会选择尽可能小的方向去进行延伸,比如我们一开始还是从顶点A开始:
此时与A相连的边有B和E,A的延伸方向有两个,此时我们只需要选择一个最小的就可以了:
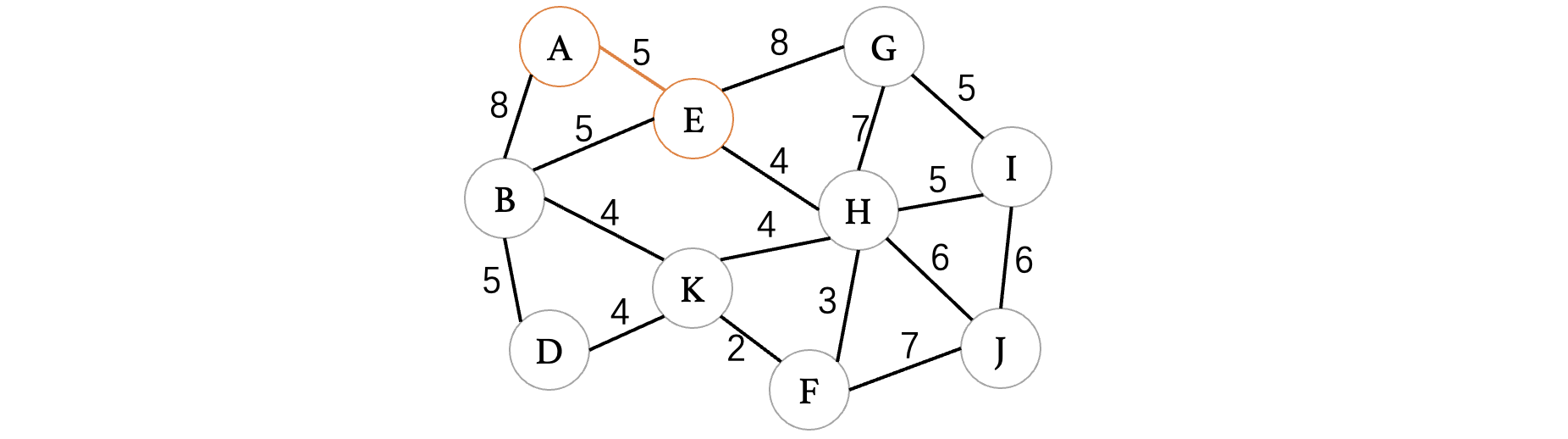
此时我们已经构建出了由A、E组成的一棵树,同样的,我们需要去寻找与当前树中A、E顶点相连的所有顶点,包括B、G、H,哪一个最小,那么下一个延伸的就是哪一个,此时发现H和E之间最小,继续延伸:
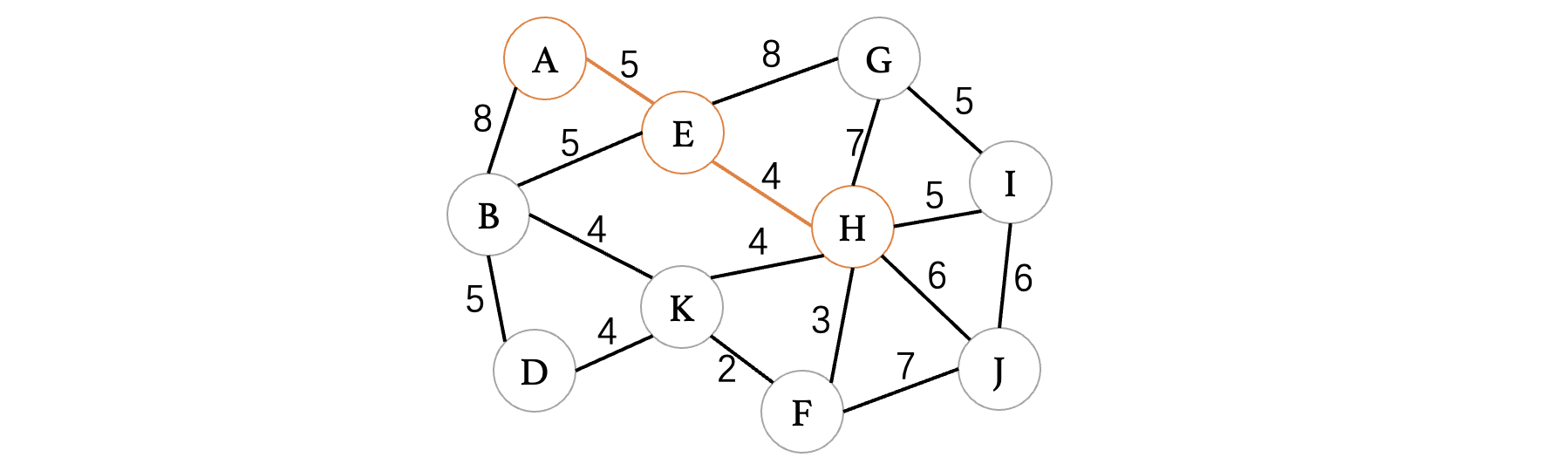
现在已经变成了由A、E、H组成的一棵树,同样的,按照之前的思路继续寻找一个最小的方向进行延伸:
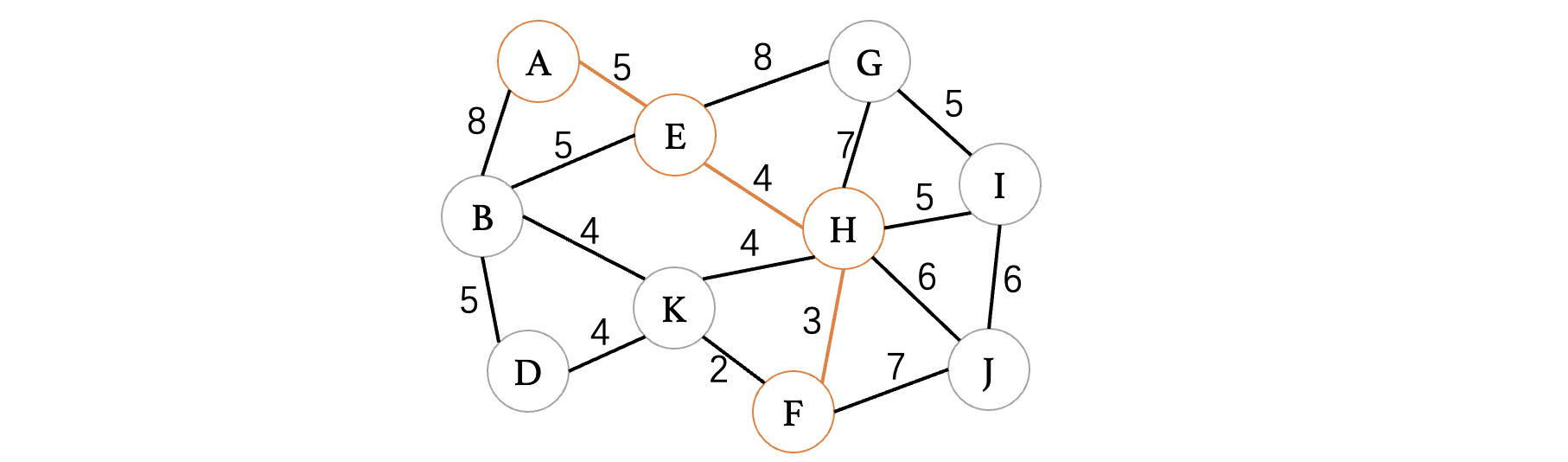
继续进行延伸,发现F、K之间最小:
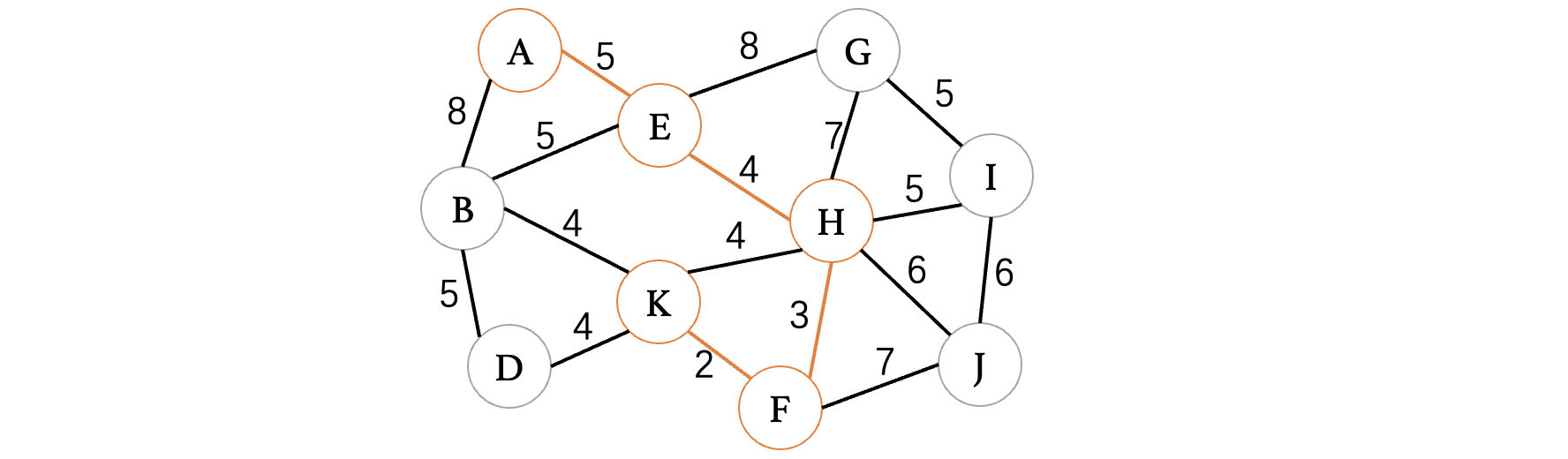
此时K、B和K、D和K、H的权重都是4,其中H顶点已经走过了,不能出现回路,所以说不考虑,此时随便选择K、B或是K、D都可以,不会影响后续结果:
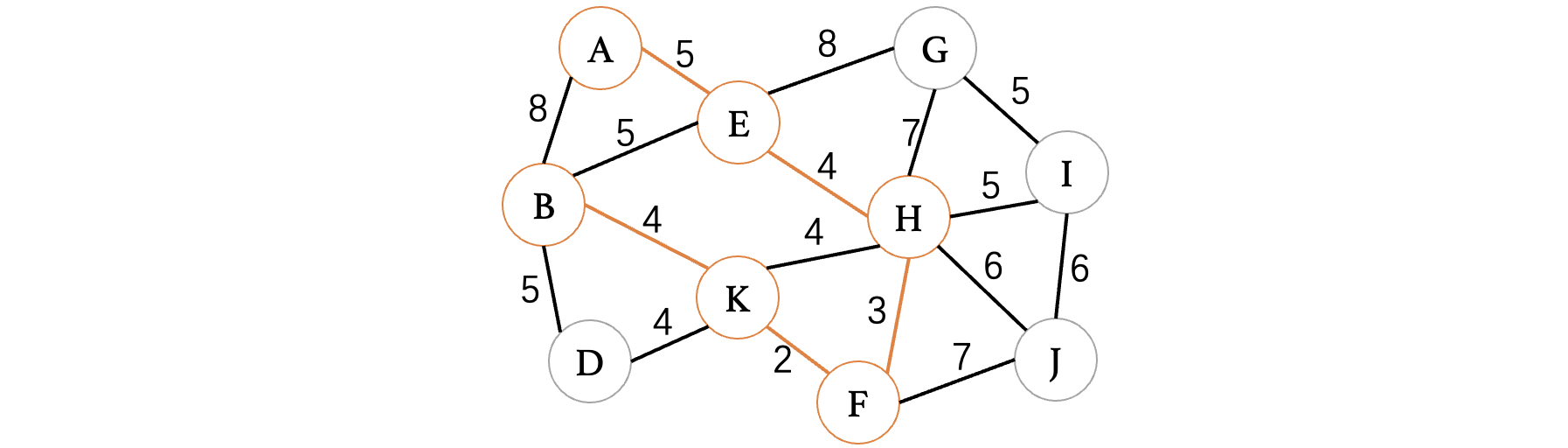
此时依然是K、D为最小,所以说直接选择:
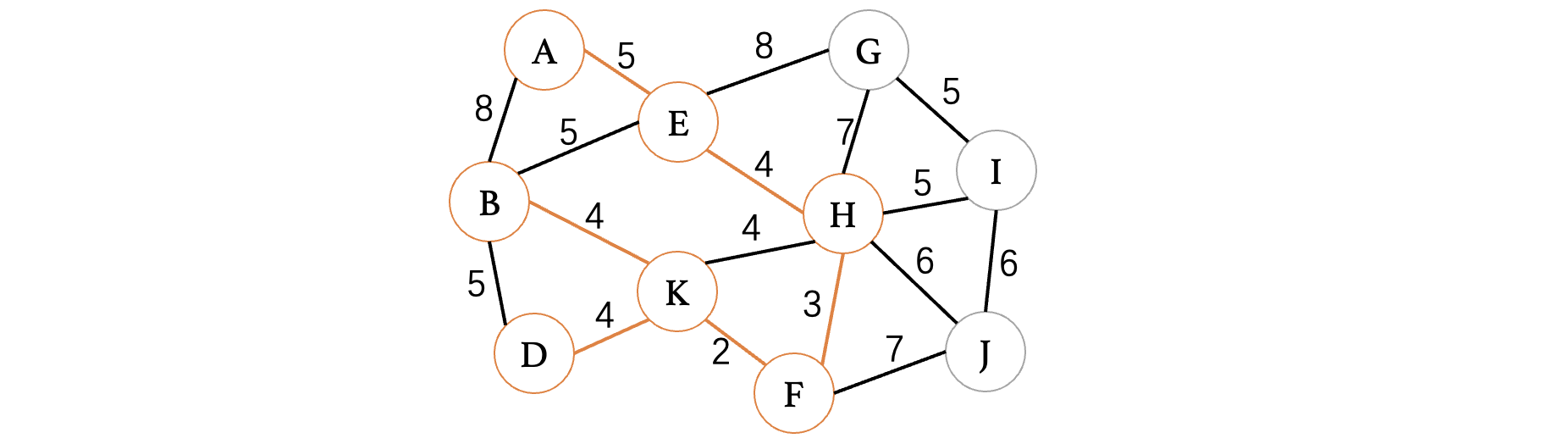
紧接着,我们发现最小权重的来到了5,此时权重为5的边有B、E和H、I和B、D,但是由于E、D已经走过,此时直接选择H、I即可:
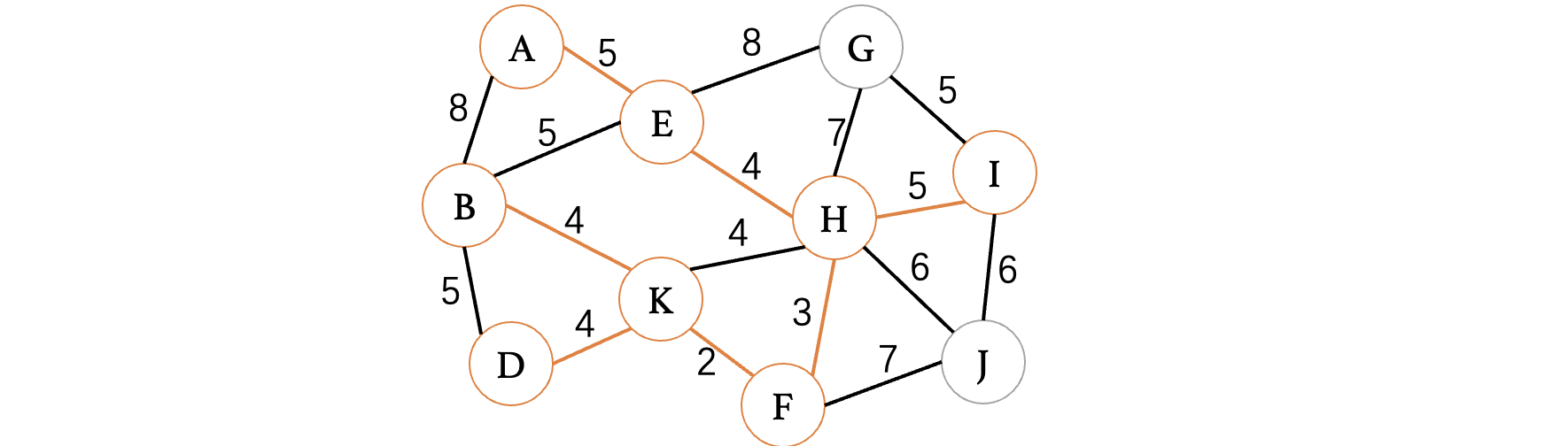
接着,我们发现I、G也是5,直接选择即可:
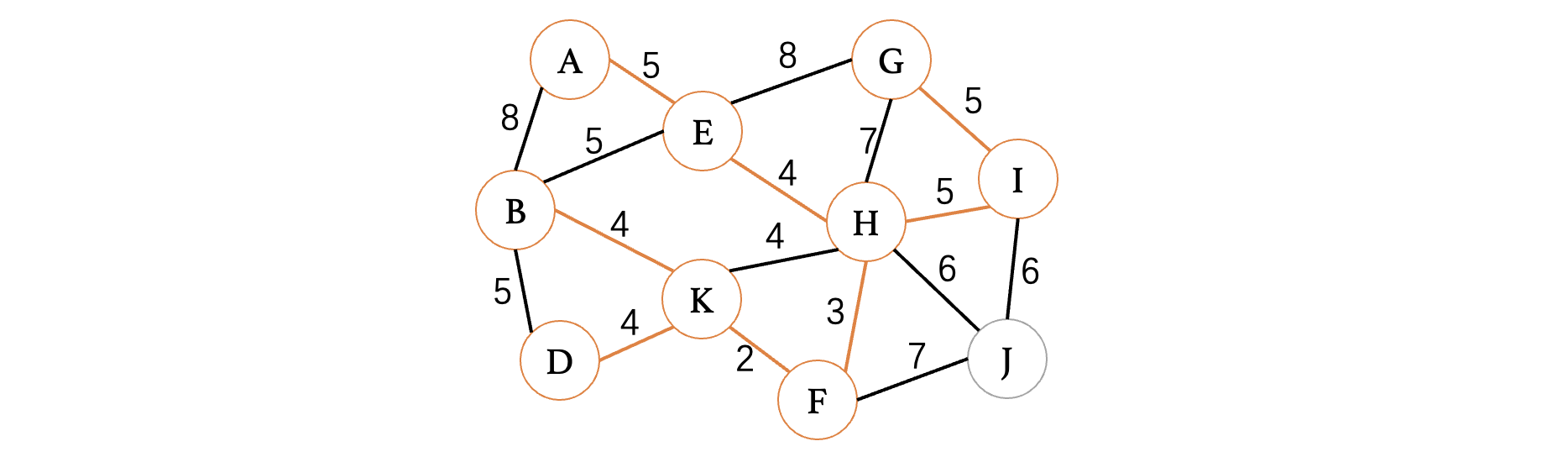
然后最小权重此时就是6了,选择H、J和I、J都可以,随便选择一个即可:
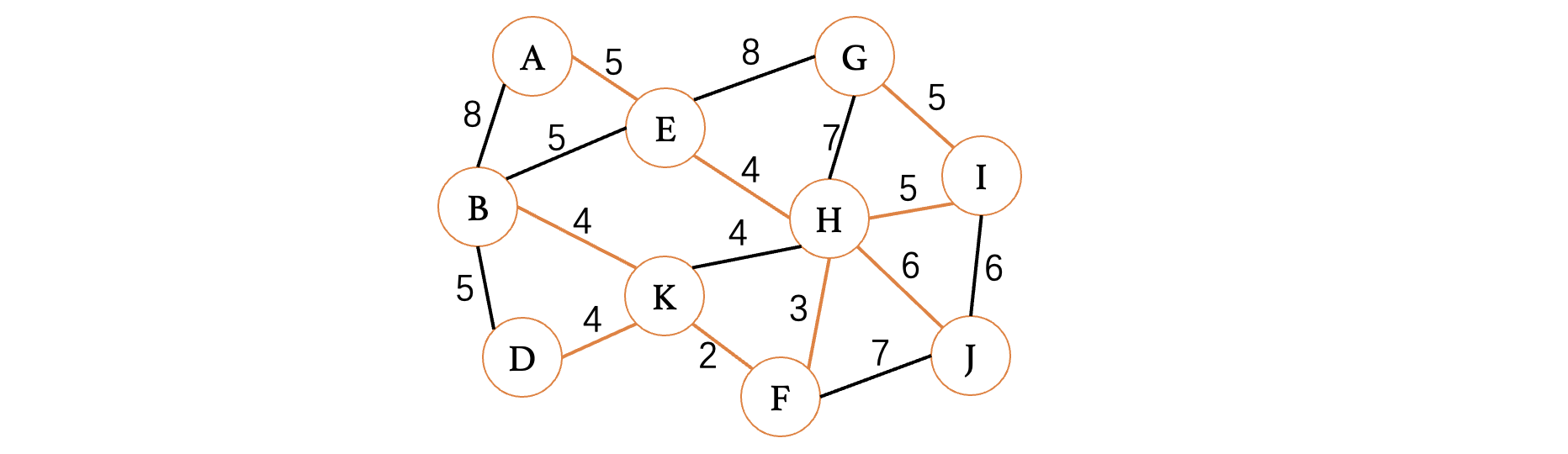
此时,整个图的所有顶点就遍历完成了,现在我们去掉那些没用被采用的边,得到的结果就是我们的最小生成树了:
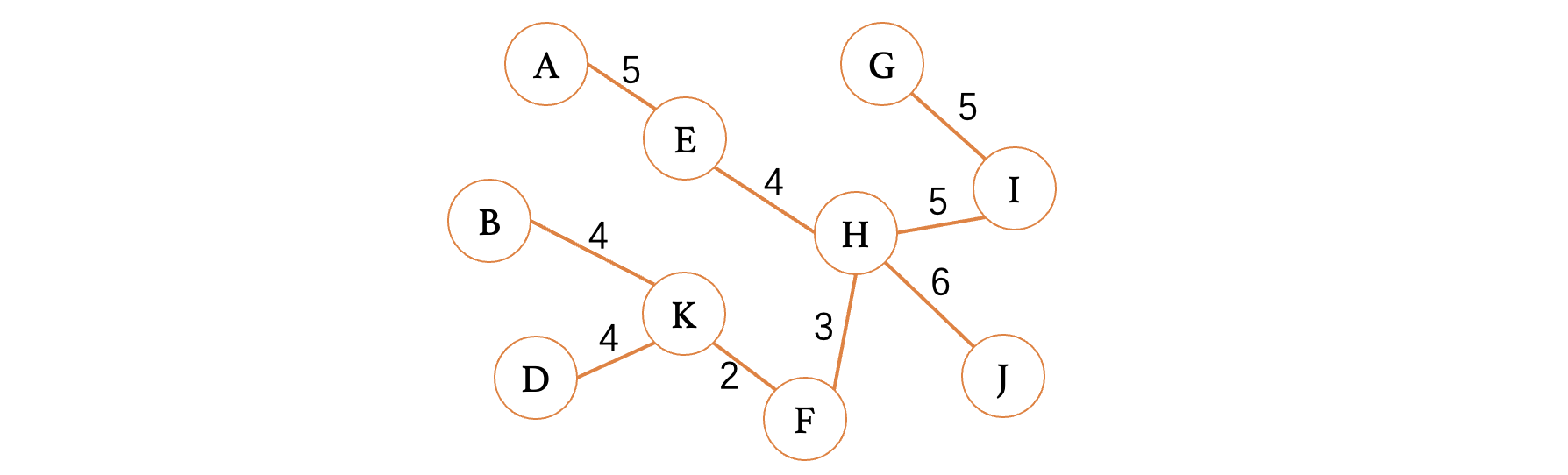
虽然样子有点丑,但是把它捋一捋就好了。可以看到省去的边都是尽可能大的边,或是那种导致回路的边,留下的边基本都是权重小的边,得到的就是最小生成树了(注意考试的时候只要按照我们的思路推是肯定没问题的,但是千万要仔细看,不要把边给看漏了,不然会出大问题)
我们接着来看另一种,克鲁斯卡尔算法,它的核心思想就是我们主动去选择那些小的边,而不是像上面一样被动地扩展延伸。
在一开始的时候,直接去掉所有的边,我们从这些边中一个一个选择出来(注意是任意一条边都可以选择,并不是只有选择的顶点旁边才能选择,这个过程中可能会出现多棵树,但是最后一定会连成一棵树的),最后形成一颗最小生成树,假设一开始什么都没选择,被选中的边我们一会用橙色标注:
首先我们直接找到最小边,K、F,它的权值为2,所以说直接选择就行:
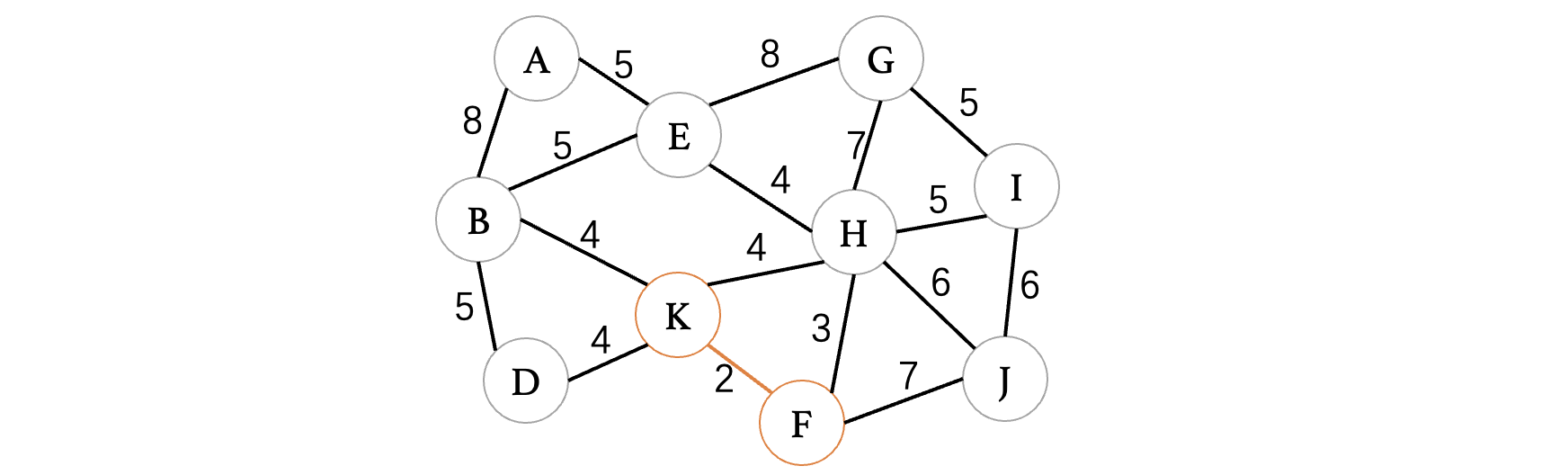
紧接着就是F、H的边,权重为3,目前最小的了:
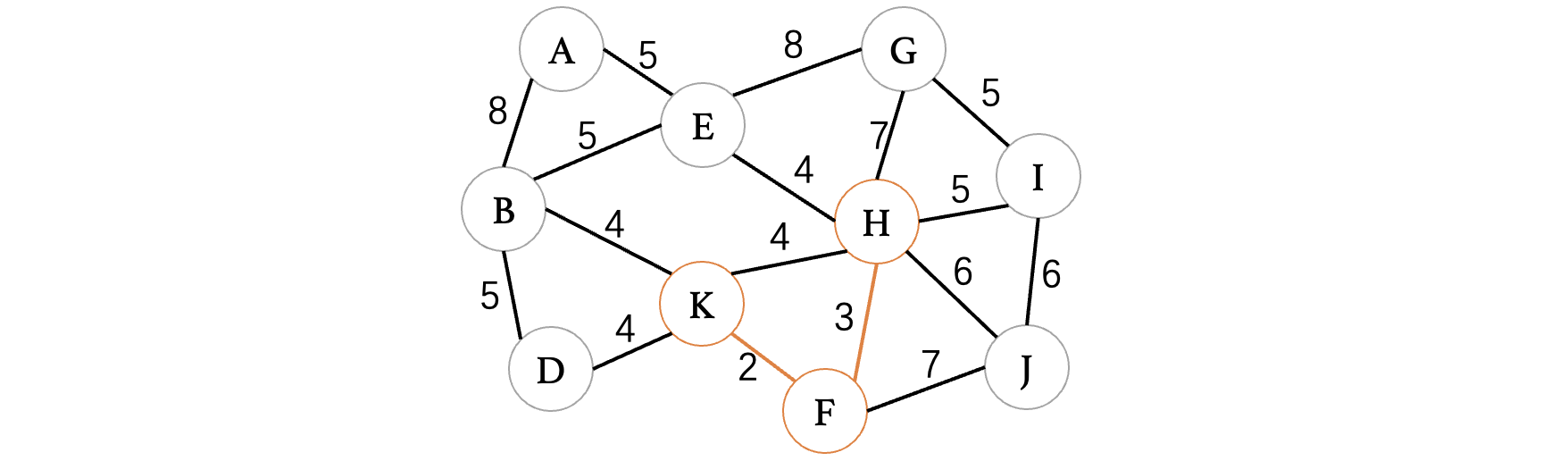
此时最小的权重就只有4了,目前有4条边都可以进行选择,但是K、H这条边因为K和H都已经在树中了,所以说不能考虑,其他三条边都是没问题的,我们随便选择一条就行了:
继续选择权重为4的边:
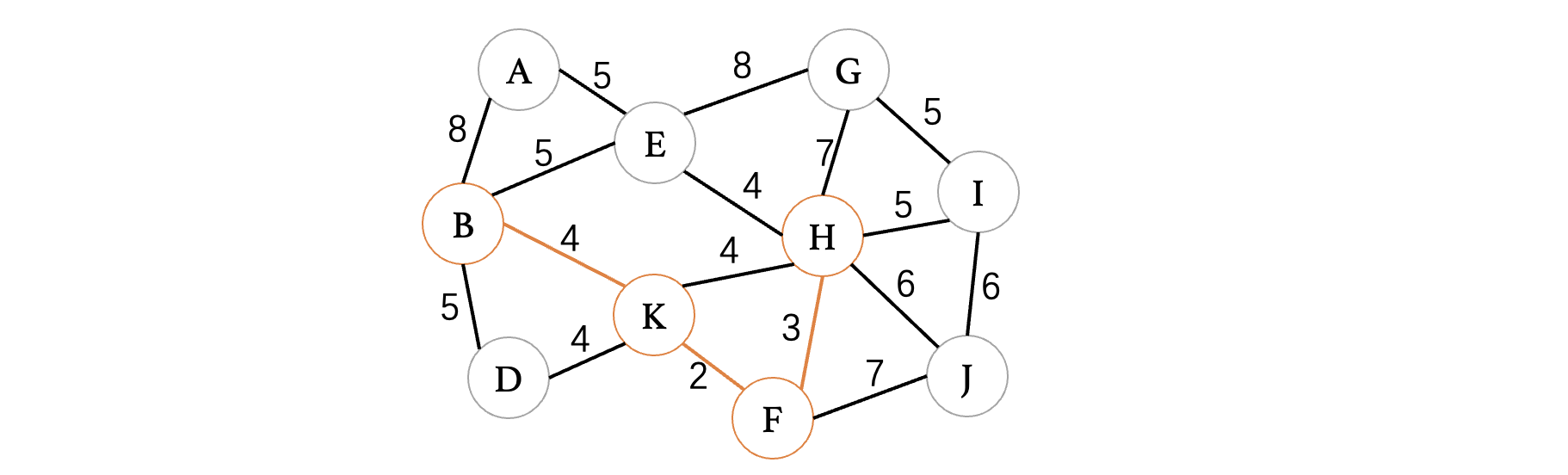
此时权重就来到了5,那么权重为5的顶点我们也可以随便选择一条,只要不会导致出现回路就行了:
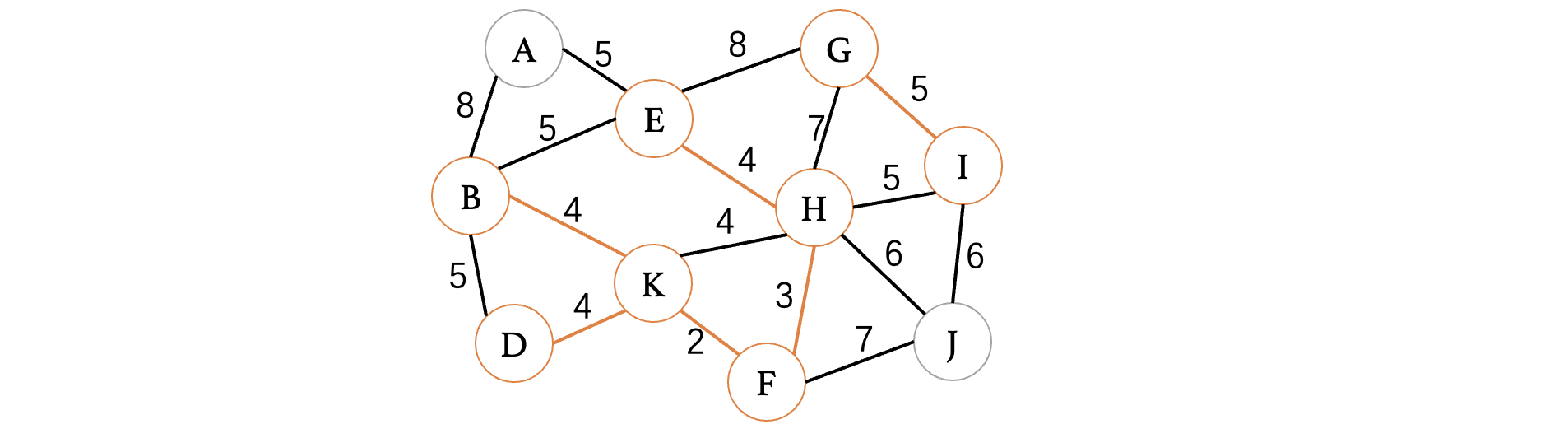
此时连接G、I,我们发现出现了两棵树,没关系的,最后会连成一棵树的,我们继续选择其他权重为5的边:
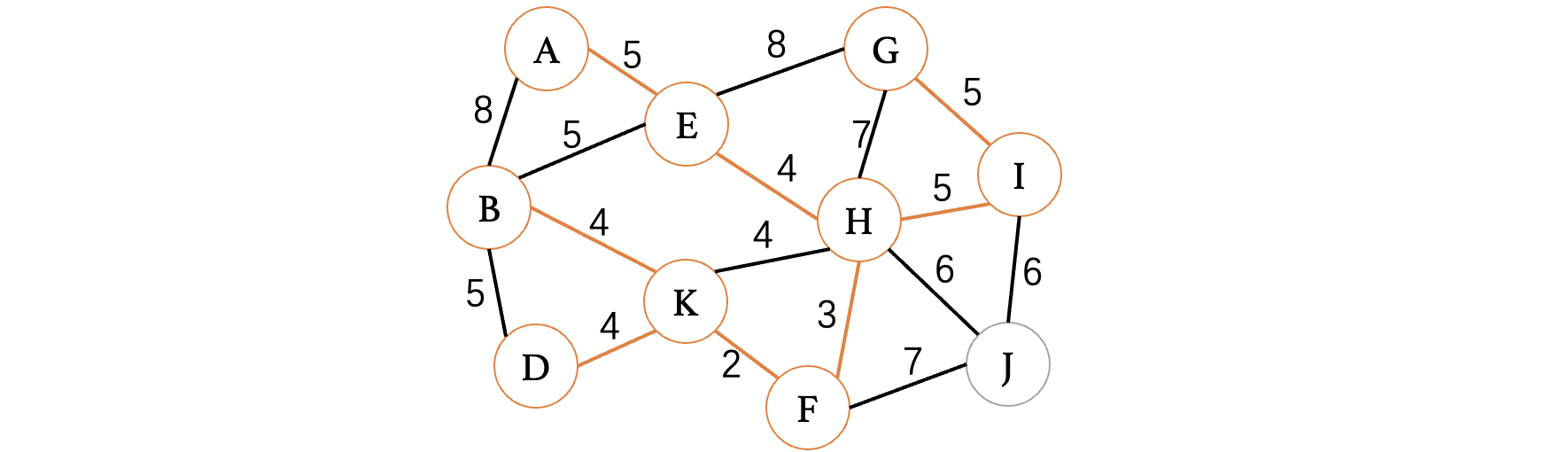
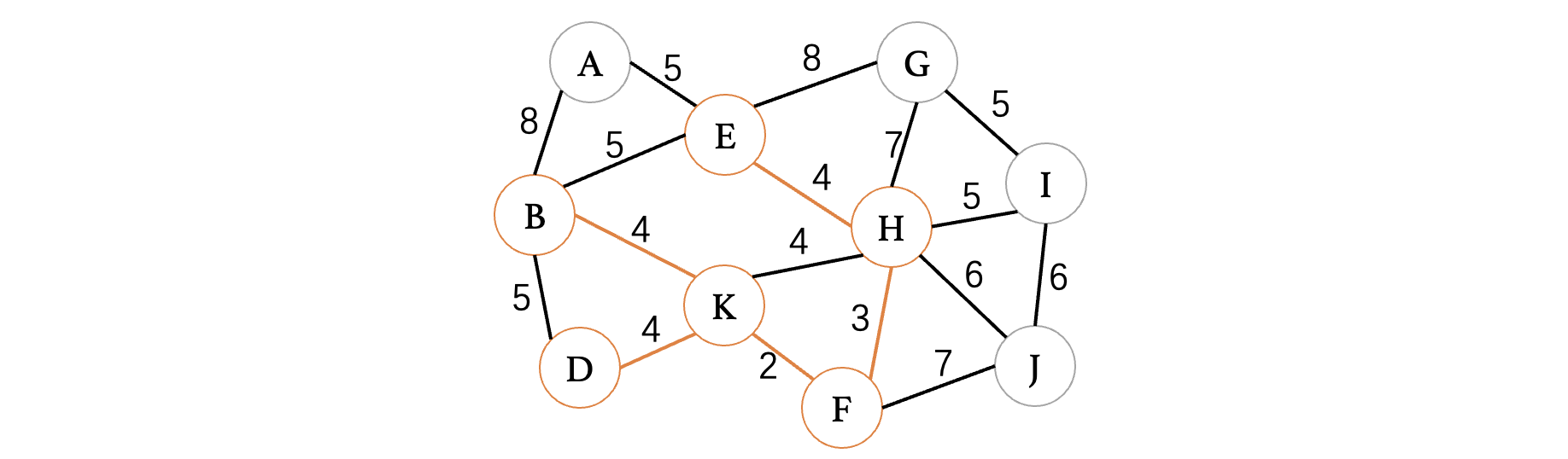
此时我们选择A、E这条边,然后是H、I这条边,虽然这条边上的H和I顶点都已经在树中了,但是它们并不属于同一棵树,这种情况也是可以连接的,然后我们继续选择权重为6的顶点:
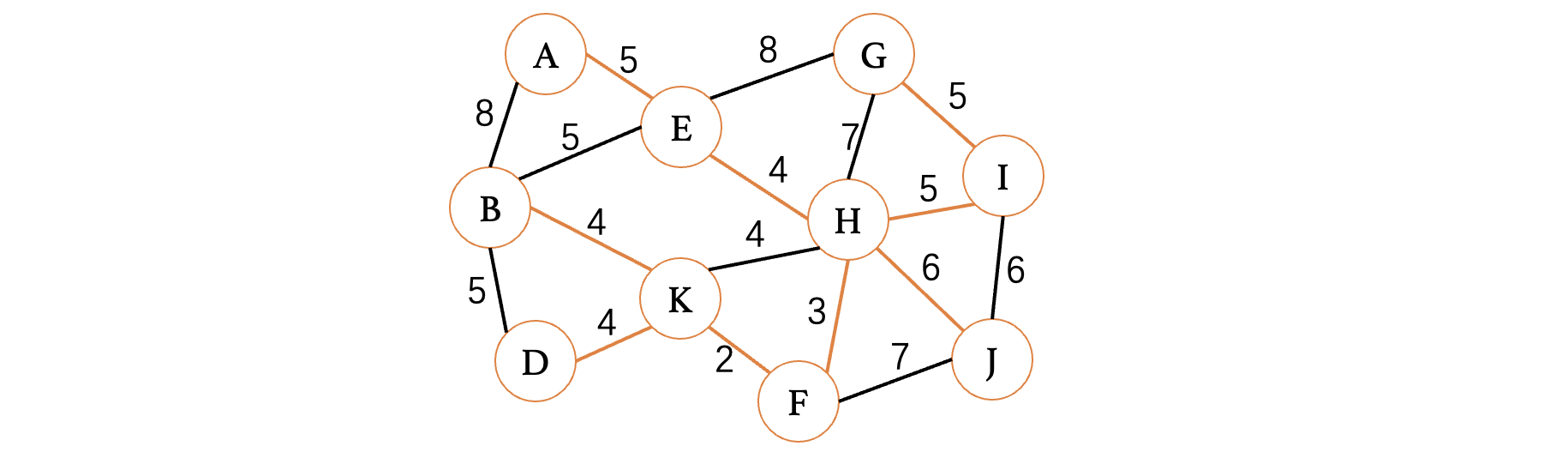
此时选择I、J或是H、J都可以(最小生成树不唯一)现在我们已经连接上所有的顶点了,最小生成树构建完成,我们把那些没有选择都边都扔了:
其实无论是哪种算法,最后都能够得到一棵最小生成树,有关实现代码,由于太过复杂,这里就不进行编写了。
最短路径问题
前面我们介绍了最小生成树,通过两种算法就能够从众多的边中选择那些尽可能小的边得到一个权重最小的树,这一块我们将继续讨论最小开销相关的问题。
地铁线路错综复杂,我们想要从一个站点坐到另一个站点,其实是有很多种方案的,比如我们可以选择少的换乘数放的方案,或是距离近的方案,不同的方案可能坐的站点数就不同,而最后我们出站时,始终是按照从A地点到B地点最小经过的站点数进行收费的(比如从A到B有两种方案,前者要坐11个站,后者要坐7个站,但是最后只会按7个站进行收费),那么这么多线路,我们要如何计算得到一条最短的路径呢?
我们首先从最简单的单源最短路径进行讨论,所谓单源最短路径,就是一个顶点出发,到其他顶点的最短路径,比如下面的这张图:
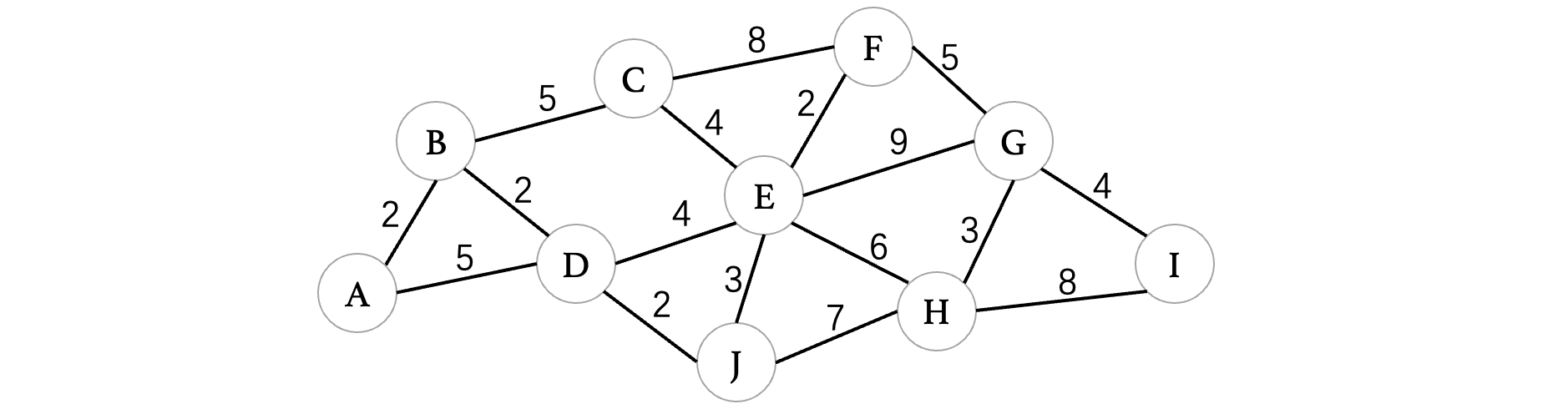
要解决这种问题,我们可以采用**迪杰斯特拉(Dijkstra)**算法,下面我们来看看迪杰斯特拉算法是如何让计算机来计算最短路径的,它跟普利姆算法求最小生成树有着很多相似之处,我们就从A出发,这里我们需要一个表来记录:

dist这一行记录A到其他顶点的最短路径,path这一行记录的是最短路径所邻接的顶点,我们首先还是从A开始,与A直接相邻的两个分别是B和D,其中B的距离是2,D的距离是5,那么我们就先进行一下记录:

因为都是从A过来的,所以说直接记录为A即可,接着我们继续找到当前A路径最短的一个顶点B,此时顶点B可以到达C、D、A,因为不能走回头路,不考虑A,那么目前从A到达C的最短距离就是经过B到达的,相当于A->B加上B->C的距离:

然后我们来看顶点D,此时我们发现,除了A直接到D之外,从B也可以到达D,那么我们就可以比较一下,看是从B到D更短一些,还是从A直接到D更短一些 min(2 + 2, 5) ,通过比较,我们发现从B绕过去会更短一些,只需要4即可,所以说我们将其更新一下:

接着我们继续找到下一个离A最近的顶点D,D与顶点E和J相连,直接更新即可,比如E的最短路径就是相当于是A到D的最短路径加上D到E的路径,D到J也是同理:

此时继续找到表中下一个距离A最近的顶点J,J可以到达H或者是E,按照同样的方式,我们看看是从D直接到E更短,还是从J到E更短,进行比较 min(6 + 3, 8) ,得到结果是D直接过去更短,所以说不需要更新。然后H更新为J过去的最短路径:

我们接着来看下一个距离A最近的顶点C,此时C可以到达F和E,我们先来看E,还是对其进行比较,如果从C到达E更短,那么就更新为新的值,$min(7 + 4, 8)$,最后仍然是从D到E最短,所以说不变,接着我们把F的值更新一下:

然后我们来看下一个距离A最近的顶点E,E连接的就比较多了,此时E最短路径是从D过来的,那么我们就不考虑D,我们来依次看看与其相连的C、F、G、H、J(注意这里比较的是从E到这些顶点,之前比较的是从这些顶点到E,不要以为是一样的了)
- 从E到达顶点C:$min(8 + 4, 7)$,故C继续采用原方案。
- 从E到达顶点F:$min(8 + 2, 15)$,此时从E到达F路径更短,更新F。
- 从E到达顶点G:直接更新。
- 从E到达顶点H:$min(8 + 6, 13)$,故H继续采用原方案。
- 从E到达顶点J:$min(8 + 3, 6)$,故J继续采用原方案。
最后得到:

我们继续来到下一个离A最近的顶点F,F连接了G和E,但是由于当前最短路径是从E过来的,不能走回头路,所以说直接去看G,比较 $min(10 + 5, 17)$,得到从F到达G会更短,所以说更新G:

然后我们接着看到下一个最短的顶点H,此时H与G和I相连,我们先来看G,$min(13 + 3, 15)$,维持原方案。然后是I,直接更新即可:

虽然此时表已经填完了,但是我们还没有把所有的顶点都遍历完,有可能还会存在更短的路径,所以说别着急,我们还得继续看。此时继续选择下一个离A最近的顶点G,它与E、F、H、I相连,由于其实从F过来的,排除掉F,我们来看看其他三个:
- 从G到达顶点E:$min(15 + 9, 8)$,显然选择原方案就行。
- 从G到达顶点H:$min(15 + 3, 13)$,依然是选择原方案更短。
- 从G到达顶点I:$min(15 + 4, 21)$,从G到达I更短,更新。
最后得到:

此时我们来看最后一个顶点I,与其连接的有G和H,因为是从G过来的,直接比较H就行了,$min(19 + 8, 13)$,维持原方案就行,至此,迪杰斯特拉算法结束。最后得到的表,就是最终的A到达各个顶点的最短路径值了,并且根据path这一栏的数据,我们就可以直接推出一条路径出来。
当然,这只是解决了单源最短路径问题,现在我们将问题的难度提升一下,比如我们现在想要求得图中每一对顶点之间的最短路径,那么该如何进行计算呢?最简单的办法就是,我们可以将所有的顶点都执行一次迪杰斯特拉算法,这样我们就可以求到所有顶点之间的最短距离了。只不过这种方式并不是最好的选择,对于这种问题,我们可以选择弗洛伊德(Floyd)算法。
比如下面的有向网图(权值别出现负数了,不然要出大问题):
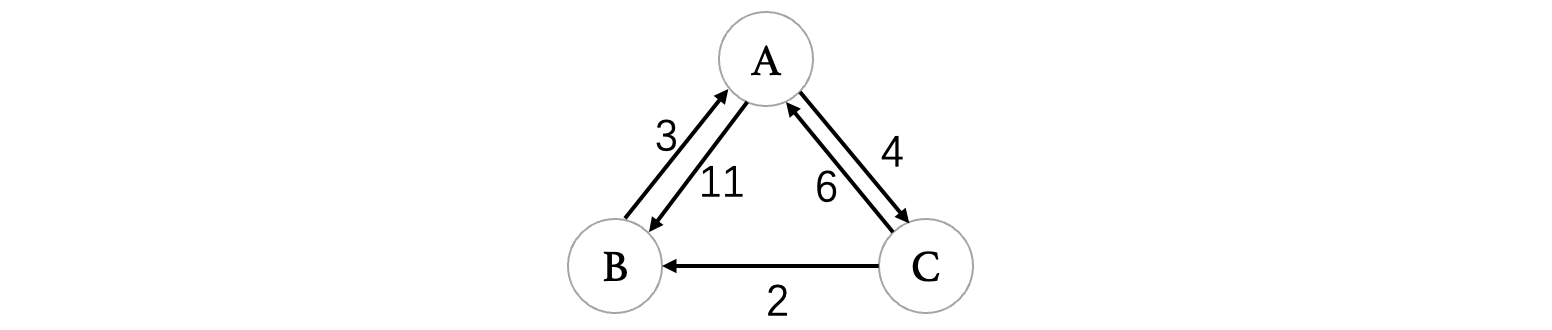
我们可以很轻松地得到它的邻接矩阵:

而弗洛伊德算法则是根据最初的邻接矩阵进行推导得出的。规则如下:
- 从1开始,一直到n(n就是顶点数)的一个矩阵序列A1、A2、...An,我们需要从最初的邻接矩阵开始,从A1开始不断往后推。
- 每一轮,我们都会去更新那些非对角线(对角线都是0,更新了还是0,所以说没必要看)、
i行i列以外的元素,判断水平和垂直方向投影的两个元素之和是否比原值小,如果是,那就更新为新的值。迭代公式为:A_k(i,j)=min(A_{k−1}(i,j), A_{k−1}(i,k)+A_{k−1}(k,j)) - 经历n轮后,最后得到的就是最终的最短距离了。
我们从第一轮开始,第一轮是基于原有的邻接矩阵来进行处理的:

此时我们看到,除了对角线以外,就是B->C和C->B的这两个位置,我们按照上面的规则,进行计算:

同样的,我们继续看到C->B这个为止,按照同样的方式进行更新:

最后更新完成得到的结果如下:

实际上我们发现,我们计算的和相当于是绕路的结果与当前直接走的结果相比较得到的。按照的同样的方式,我们开始第二轮:

更新完成之后,C->A的距离变成了5:

我们接着来看最后一轮:

此时我们将A->B的距离也更新一下:

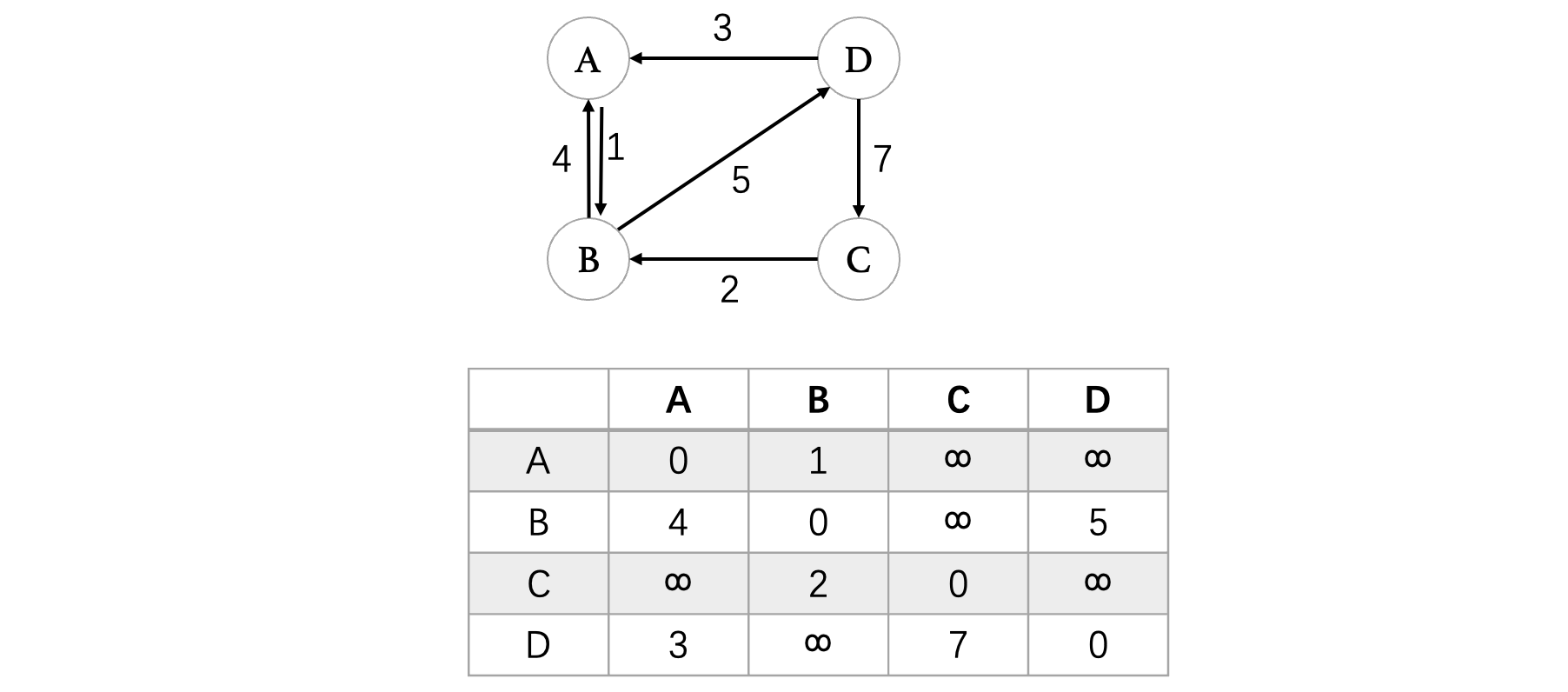
最后我们得到的矩阵,存放的就是所有顶点之间的最短距离了,当然这里我们只计算了最短距离,没有去记录从哪个方向到达此顶点的,各位小伙伴也可以在计算的同时单独在另一个表中记录一下从哪个顶点过去计算出来的最小距离,这里就不演示了。实际上这个算法对我们来说是更好理解的一种算法,并且在编写程序时也会很简单,我们以下图为例:
代码如下:
#define INF 210000000
#define N 4
int min(int a, int b){
return a > b ? b : a;
}
void floyd(int matrix[N][N], int n){
for (int k = 0; k < n; ++k) //一共需要执行K轮
for (int i = 0; i < n; ++i) //i和j从0开始就行了,直接全看,不会影响结果的
for (int j = 0; j < n; ++j)
matrix[i][j] = min(matrix[i][k] + matrix[k][j], matrix[i][j]); //按照规则更新就行了
}
int main(){
int matrix[N][N] = {{0, 1, INF, INF},
{4, 0, INF, 5},
{INF, 2, 0, INF},
{3, INF, 7, 0}};
floyd(matrix, N);
for (int i = 0; i < N; ++i) {
for (int j = 0; j < N; ++j)
printf("%d ", matrix[i][j]);
putchar('\n');
}
}
最后得到的结果为:

经过对比,确实是最短的路径了。
拓扑排序
我们接着来看拓扑排序,实际上我们生活中可能会遇到下面的问题:
比如我们的大学课程的学习,一些课程开启可能需要修完一些前置课程,比如数据结构开课需要先修完C语言程序设计,Java开课需要修完计算机网络、计算机组成原理等课程,我们在到达某个阶段之前,需要完成一些前置条件才可以解锁。包括我们游戏中的任务,需要先完成哪些主线任务,完成哪些支线任务,才能解锁新的阶段。
我们可以将这些任务都看做是一个顶点,最后就能够连接成一个有向图:
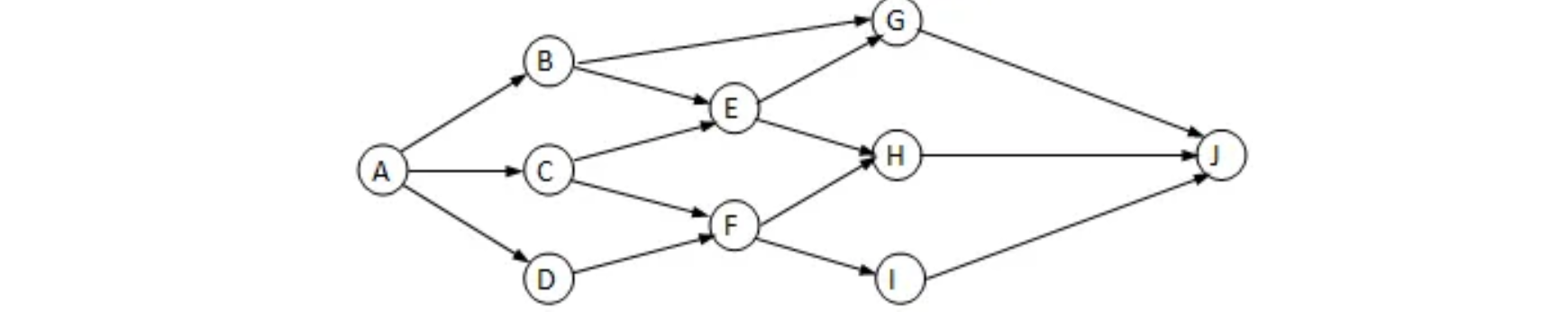
因为始终是由前置条件来解锁后续,所以说整个图中是不可以出现循环的(要是有循环的话就没办法继续了,就像先有鸡还是先有蛋的问题一样)所以说构建出来的这种图我们也称为有向无环图(DAG),其实按照我们通俗的话来说,它就是个流程图罢了,我们只需要按照这个流程图来进行即可。像这种顶点表示活动或任务的图也称为AOV图。
拓扑排序(Topological Order)是指,将一个有向无环图(Directed Acyclic Graph)进行排序进而得到一个有序的线性序列。
比如上图的拓扑排序可以是以下的几种:
- A,B,C,D,E,F,G,H,I,J
- A,C,D,B,E,F,G,H,I,J
- A,D,C,B,E,F,G,H,I,J
- A,B,D,C,E,F,G,H,I,J
只要我们保证前置任务在后续任务之前完成即可,前置任务的完成顺序不做要求,所以拓扑排序不唯一。
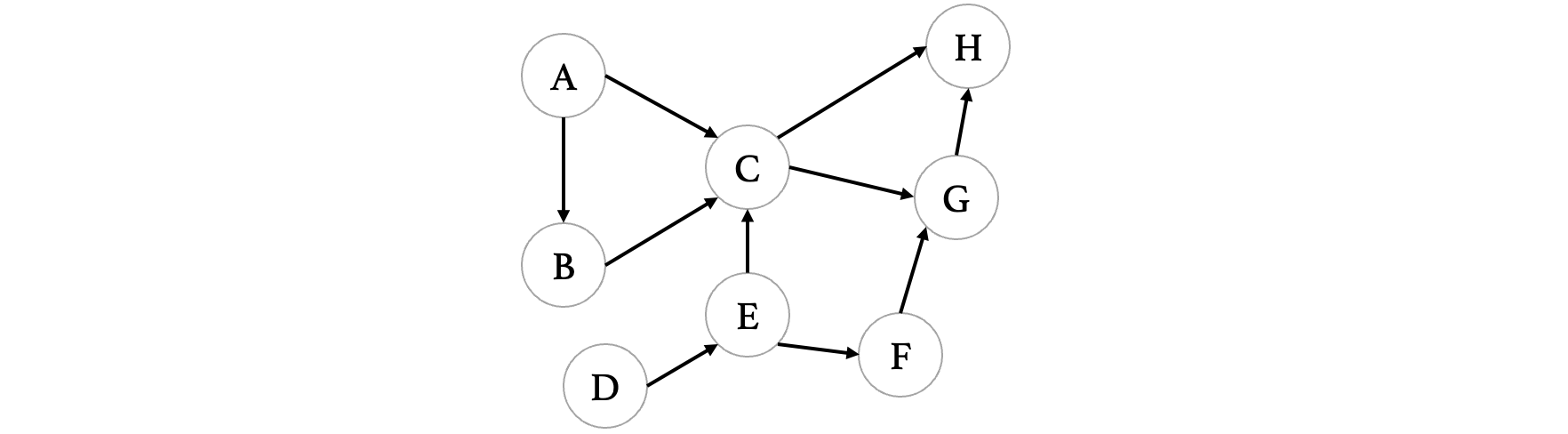
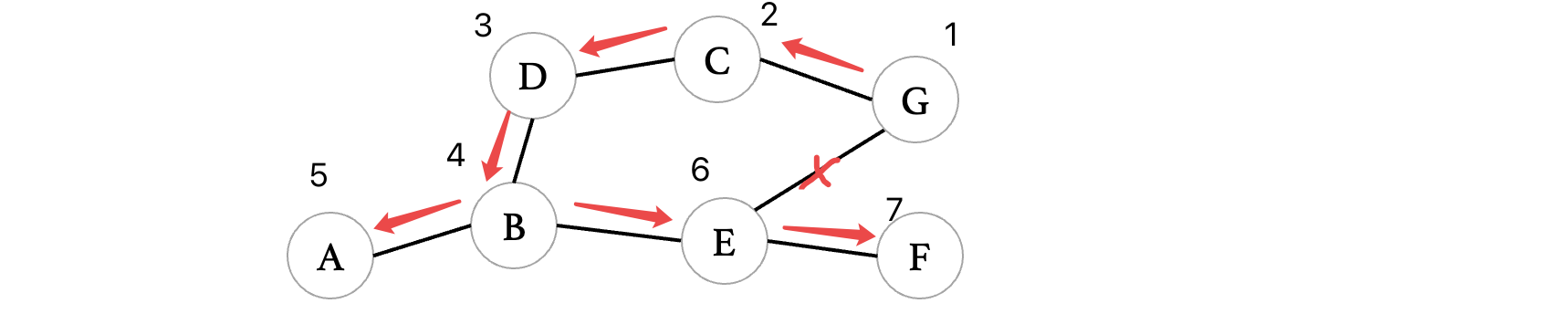
那么我们在程序中如何对一个有向无环图进行拓扑排序呢?以上图为例,其实很简单,我们还是利用队列来完成,我们每次只需要将那些入度为0的顶点,丢进队列中(注意丢进去之后记得更新一下图中其他顶点的入度)首先从A:
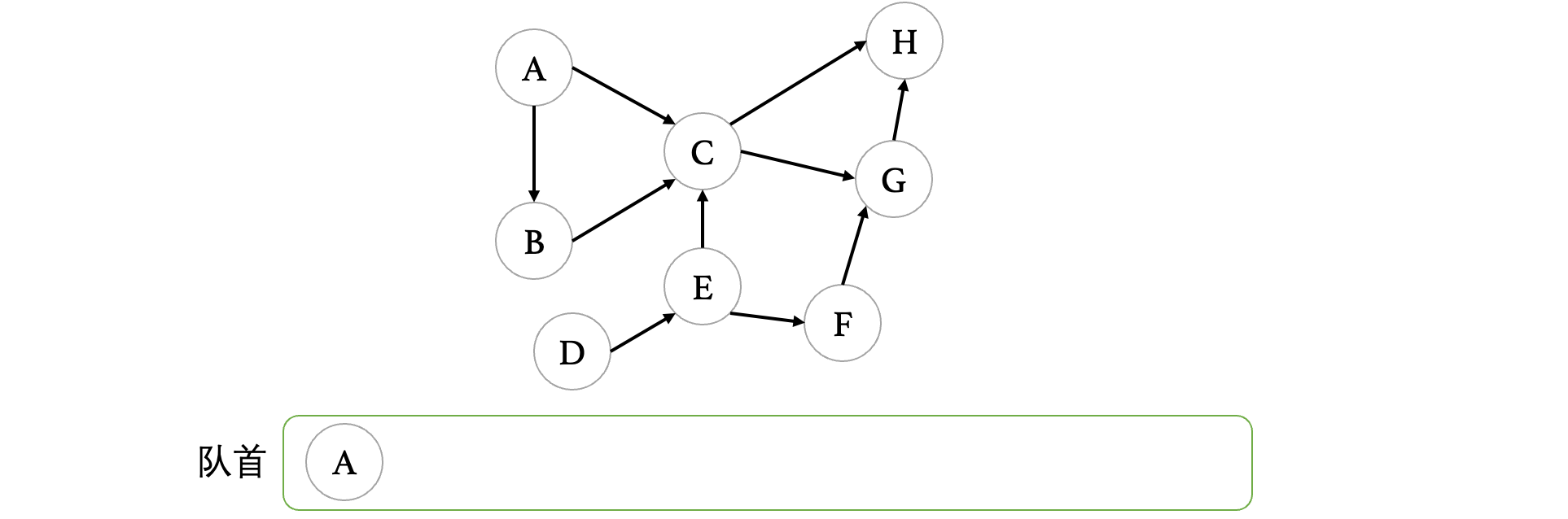
此时队列中有A这个顶点,接着我们来看看图中剩余的顶点,哪些又是入度为0的顶点,可以看到D也是:
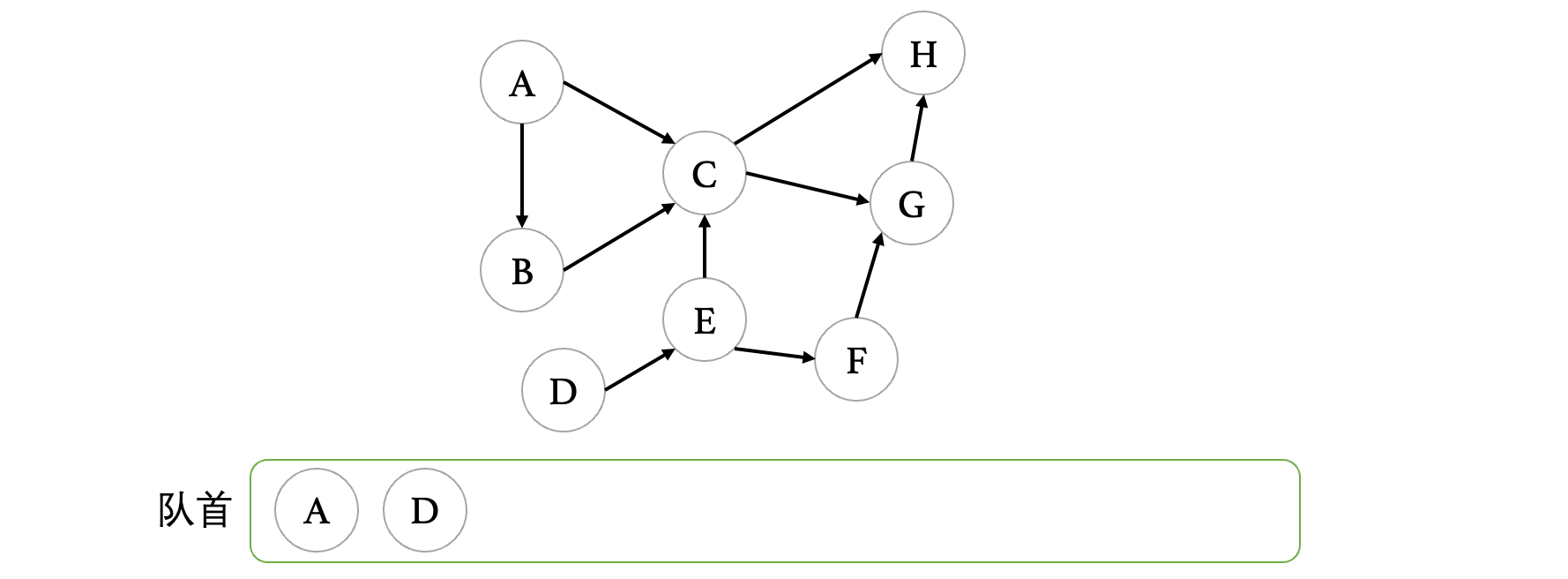
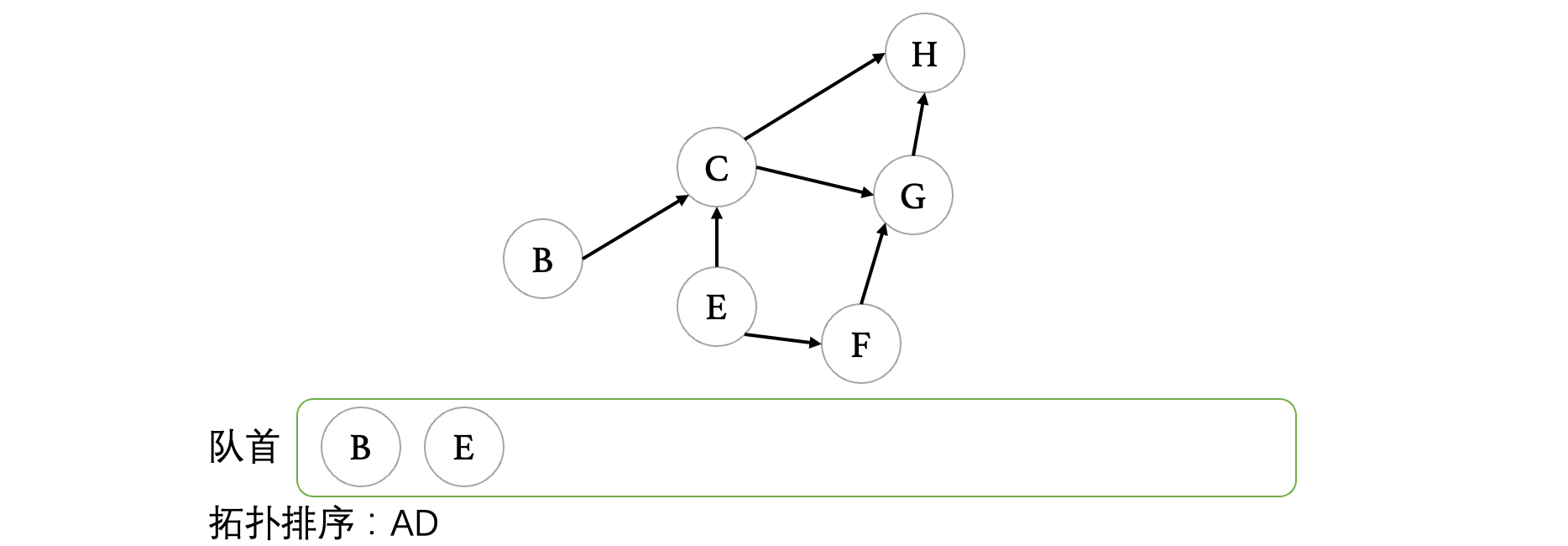
当目前所有度数为0的顶点进入队列之后,我们开始出队,正式开始拓扑排序,在出队时直接打印,并且查看,当此顶点离开图之后,图中会不会有其他顶点的入度变为0,如果有,将其他顶点入队。比如此时A出队之后,那么A要从图中移除,现在B也变成了入度为0的顶点,所以说将B丢进队列:
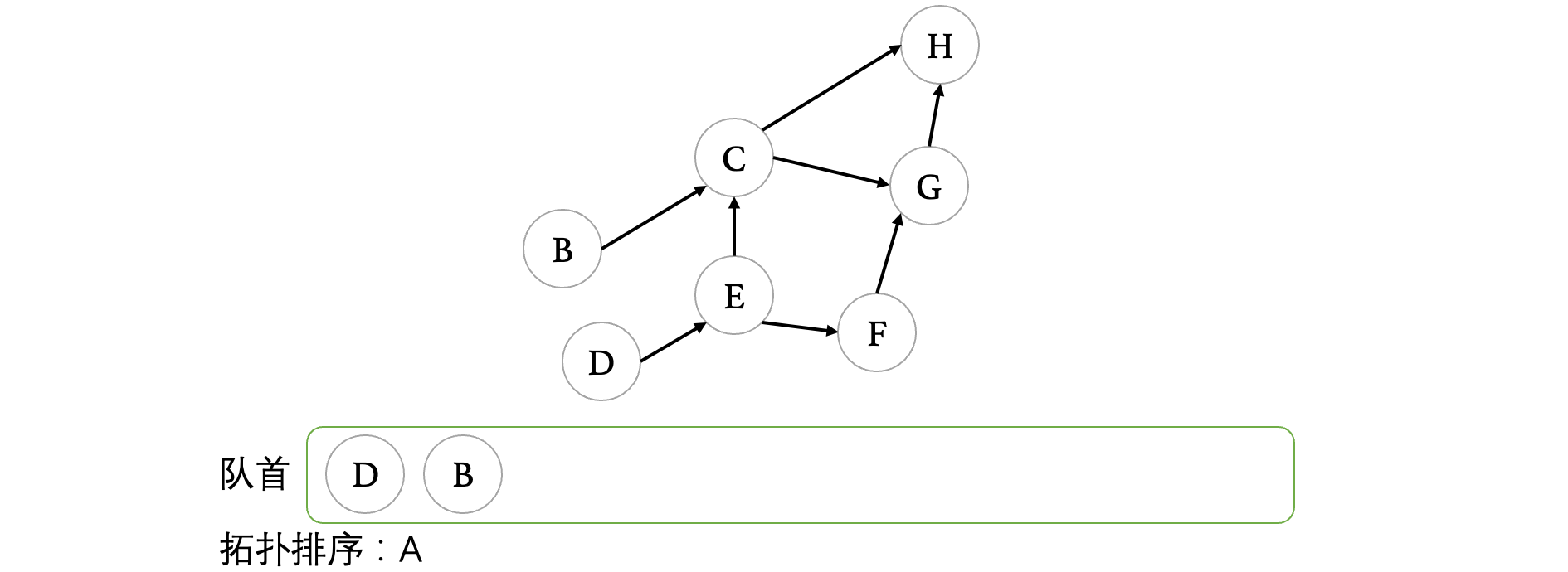
接着,我们继续让D出队,我们发现D出队之后,E变成了入度为0的顶点,所以说将E入队:
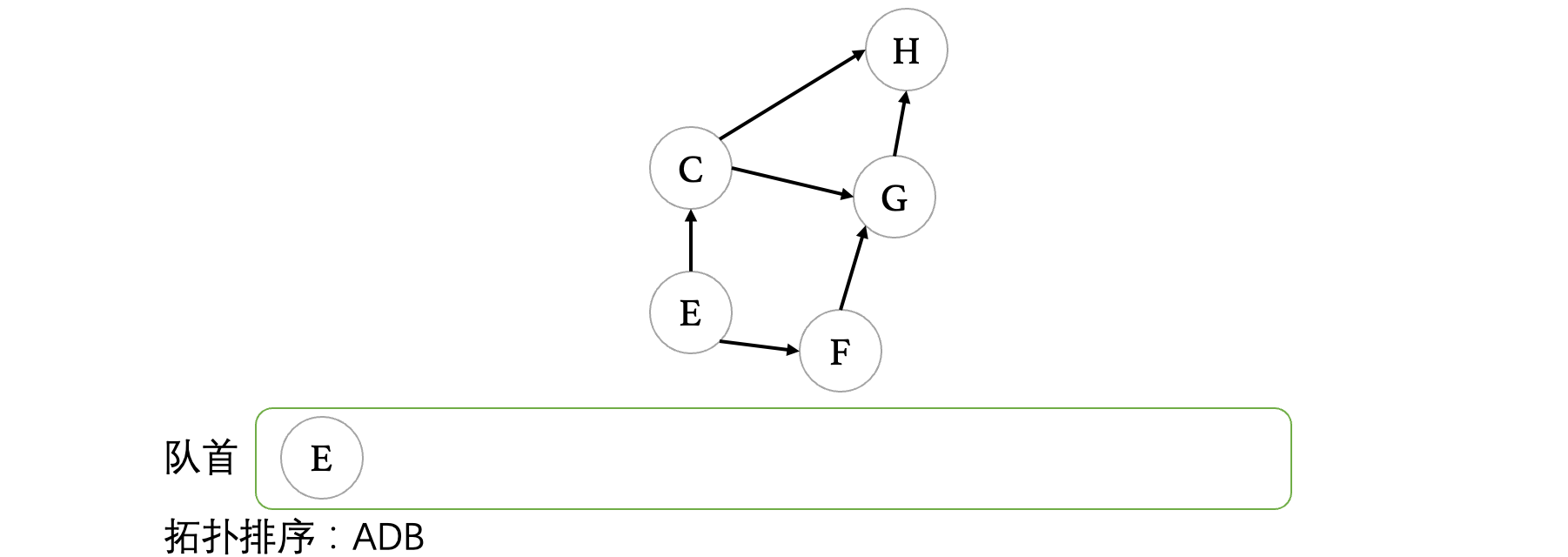
接着我们继续出队,B出队之后,我们发现没有任何顶点入度变为0了,所以说不管,继续:
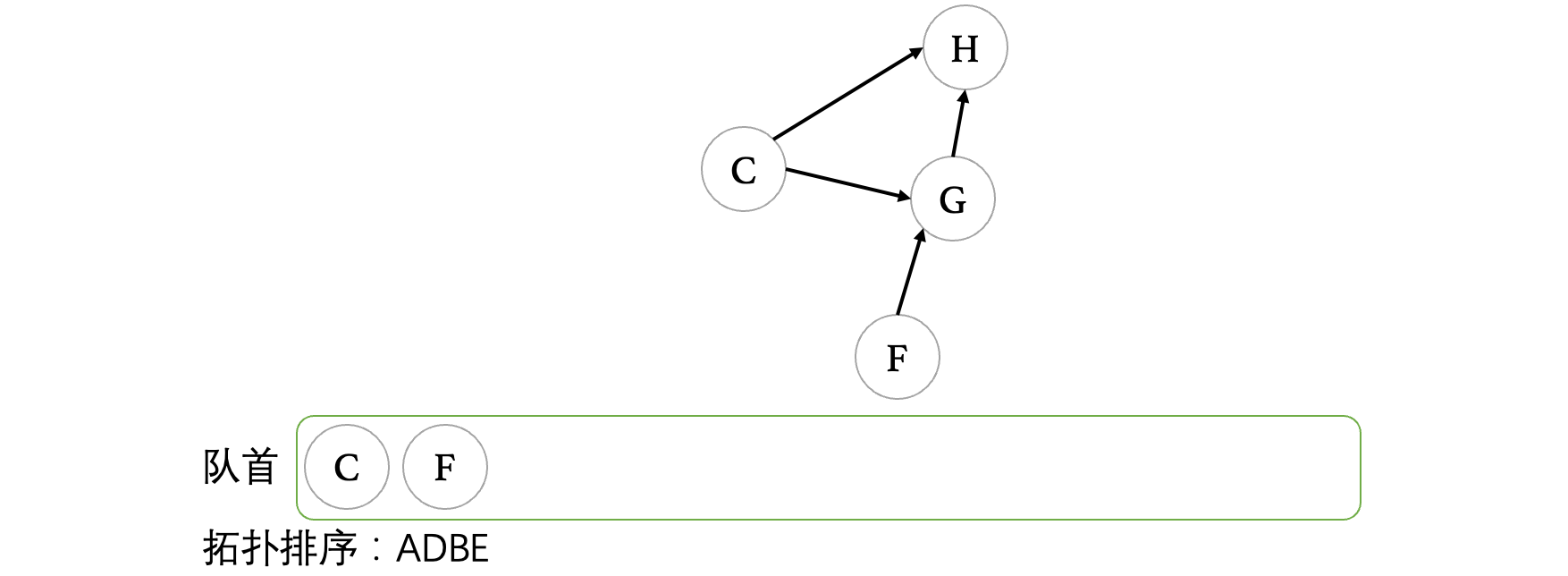
继续将E出队,在E出队之后,顶点F、C都变成了入度为0的顶点,统统入队:
此时继续将C出队,我们发现没有任何顶点入队变为0,我们继续来看F:
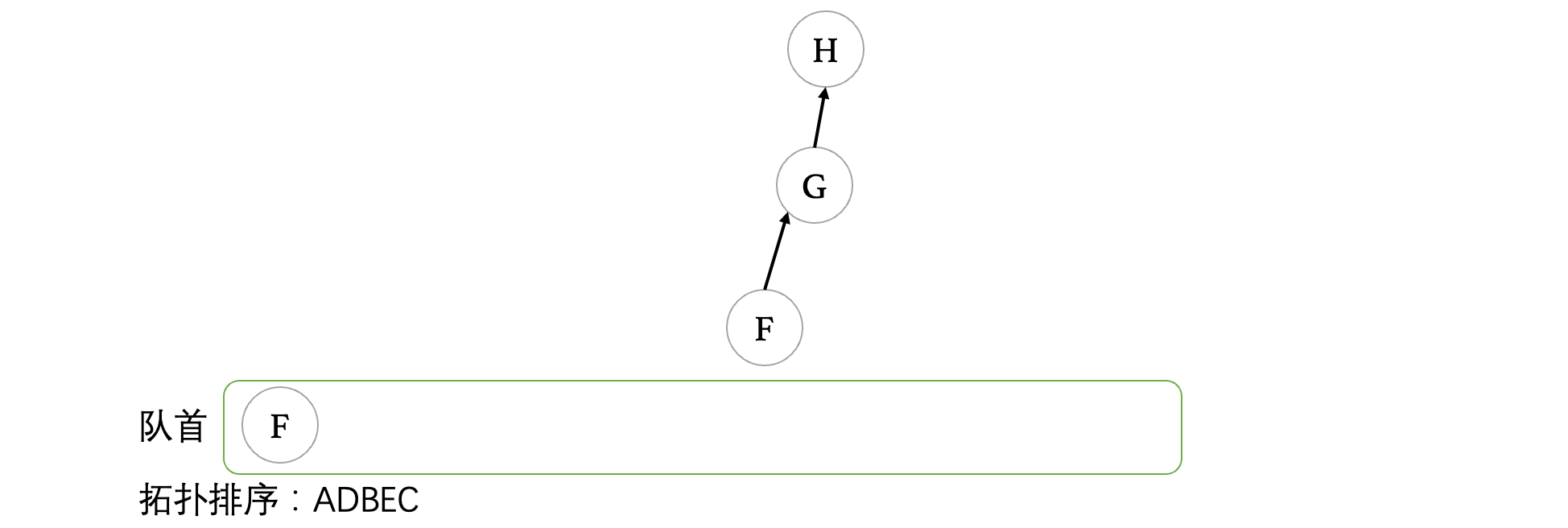
当F出队后,顶点G变成了入度为0的顶点,此时将G入队:
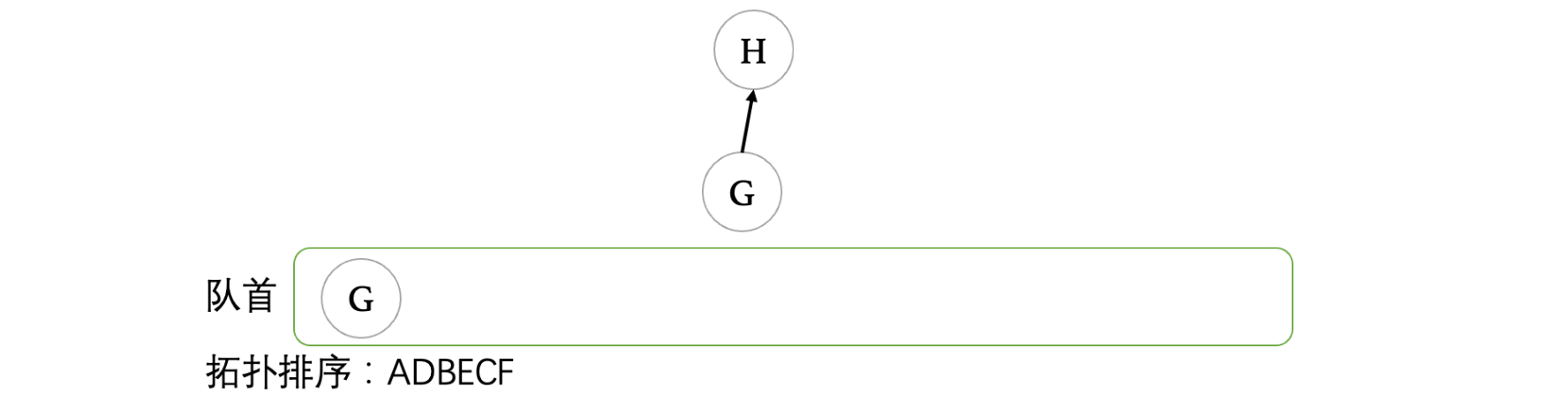
剩下就是把G出队,然后F入队F再出队了:

最后得到的拓扑序列为:ADBECFGH,其实思路还是比较简单的,当然,其实我们利用拓扑排序算法可以检测一个有向图是否为有向无环图,也就是说顶点还没遍历完队列就空了的话,说明一定出现了回路。
关键路径计算
经过前面的学习,我们知道一个任务可能会存在前置任务,只不过我们仅仅是简单讨论了任务的完成顺序,如果此时我们为每个任务添加一个权重,表示任务所需要花费的时间,那么我们的后续任务就需要前置任务全部按时间完成之后才能继续:
比如A代表某个任务(事件),B代表另一个任务,我们需要先花费2天时间完成A之后,才能开始B,活动包括时间用边来表示,我们将边作为活动的图称为AOE图,每个事件对应着多个活动(多条边)它就像一个大工程一样,从A开始,中间需要经过各种各样的步骤,最后到H完工作为结束。
而我们需要计算的是那些最拖延工期的活动,比如要开始任务C,那么需要完成A、B才可以,完成A需要7天,完成B需要5天,由于C需要同时完成A和B才能继续,所以说A就变成了最拖延工期的任务,因为它的时间比B还长,B都完工了,还需要等待A完成才可以。只要计算出这些最拖延工期的任务,得到一条关键路径,我们就可以得到完成整个工程最早的时间以及各项任务可以在什么时候开工了。
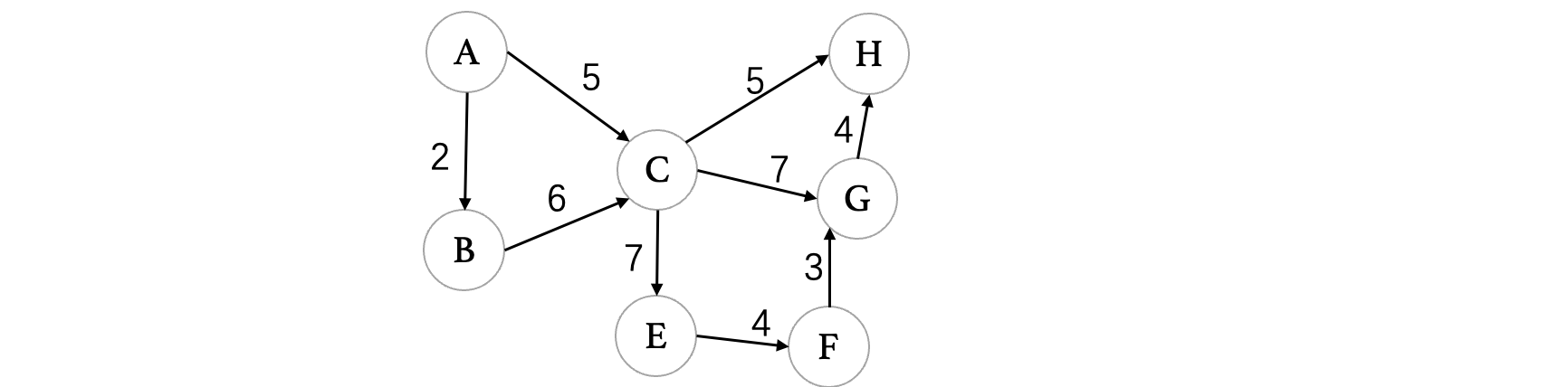
我们来看看如何进行计算,我们以下图为例:
我们需要计算两个东西,一个是事件最早完成时间(也就是要完成这个事件最快要多久),还有一个是事件最晚开始时间(就是这个事件在不影响工期的情况下最晚可以多久开始):

我们依然是按照之前的拓扑排序的顺序进行,首先一开始是A,因为只有一个起点A肯定是可以直接开始的,所以说最早和最晚时间都是0(注意如果出现多个起点的话,最晚开始时间就不一定了),我们接着AOE图的工作顺序,来计算任务B和C的最早和最晚时间:

接着就是D和E,首先D需要B和C同时完工之后才能继续,那么也就是说需要选择B和C过来时间最长的那一个:

最后就是F,到达F一共有三条路径,我们依然是选择最长的那一条,从D过来总共需要8天时间:

故整个工程的最早完成时间为8天,我们接着来看活动的最晚开始时间,现在我们要从终点倒着往回看:

首先终点一定是8,因为工期最快是在8天结束的,我们继续倒着往回走,先来看E,E需要6天才能到达,但是只需要1天就可以结束,所以 8 - 1 = 7,最晚可以在第7天时动工:

然后是D,因为D到F需要2天时间,而D已经是第6天了,总时间8天,所以说D刻不容缓,第6天就需要马上开工:

然后是C,C比较复杂,因为C有两个活动,一个是指向D的,一个是指向F的,我们需要单独计算每一个活动:
- C -> F:用F的最晚开始时间减去任务时间 = 8 - 3 = 5,此时C最晚可以从第5天开始。
- C -> D:用D的最晚开始时间减去任务时间 = 6 - 4 = 2,此时因为C的最早开始时间就是2,所以说C不能晚点开始。
综上,C不能晚点开始,只能从第2天就开始,因为要满足D的条件:

最后是B,B也是有两个任务,一个是指向E一个是指向D:
- B -> E:用E的最晚开始时间减去任务时间 = 7 - 3 = 4,此时B最晚可以第4天开工。
- B -> D:用D的最晚开始时间减去任务时间 = 6 - 2 = 4,同上。
所以,B的最晚开始时间可以是第4天:

当然最后我们也可以计算一下A -> B和A -> C,但是由于只有这一个起点,所以说算出来肯定是0,当然如果出现多个起点的情况,还需要进行计算得到的。
计算完成之后,我们就可以得到关键路径了,也就是那些最早和最晚时间都一样的顶点(说明是刻不容缓的,时间很紧)这些顶点连成的路线,就是我们要找的关键路径了:A -> C -> D -> F,这条路径被安排的满满当当。关键路径上的所有活动都是关键活动,整个工期就是由这些活动在决定的,因此,我们可通过适当加快关键活动来缩短整个项目的工期,但是注意不能加快得太猛,因为如果用力过猛可能会导致关键路径发生变化。当然,关键路径并不是唯一的,可能会出现一样的情况。
至此,有关图结构相关的内容,我们就讲解到这里。