19 KiB
什么是APM
随着微服务架构的流行,一次请求往往需要涉及到多个服务,因此服务性能监控和排查就变得更复杂
- 不同的服务可能由不同的团队开发、甚至可能使用不同的编程语言来实现
- 服务有可能布在了几千台服务器,横跨多个不同的数据中心
因此,就需要一些可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题,这就是APM系统,全称是(Application Performance Monitor,当然也有叫 Application Performance Management tools)
APM最早是谷歌公开的论文提到的 Google Dapper。Dapper是Google生产环境下的分布式跟踪系统,自从Dapper发展成为一流的监控系统之后,给google的开发者和运维团队帮了大忙,所以谷歌公开论文分享了Dapper。
技术选型
市面上的全链路监控理论模型大多都是借鉴Google Dapper论文,重点关注以下三种APM组件:
- Zipkin:由Twitter公司开源,开放源代码分布式的跟踪系统,用于收集服务的定时数据,以解决微服务架构中的延迟问题,包括:数据的收集、存储、查找和展现。
- Pinpoint:一款对Java编写的大规模分布式系统的APM工具,由韩国人开源的分布式跟踪组件。
- Skywalking:国产的优秀APM组件,是一个对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统。现在是Apache的顶级项目之一。
选项就是对比各个系统的使用差异,主要对比项:
- 探针的性能 主要是agent对服务的吞吐量、CPU和内存的影响。微服务的规模和动态性使得数据收集的成本大幅度提高。
- collector的可扩展性 能够水平扩展以便支持大规模服务器集群。
- 全面的调用链路数据分析 提供代码级别的可见性以便轻松定位失败点和瓶颈。
- 对于开发透明,容易开关 添加新功能而无需修改代码,容易启用或者禁用。
- 完整的调用链应用拓扑 自动检测应用拓扑,帮助你搞清楚应用的架构
三者对比如下:
| 对比项 | zipkin | pinpoint | skywalking |
|---|---|---|---|
| 探针性能 | 中 | 低 | 高 |
| collector扩展性 | 高 | 中 | 高 |
| 调用链路数据分析 | 低 | 高 | 中 |
| 对开发透明性 | 中 | 高 | 高 |
| 调用链应用拓扑 | 中 | 高 | 中 |
| 社区支持 | 高 | 中 | 高 |
综上所述,使用skywalking是最佳的选择。
SkyWalking 是什么

SkyWalking是一款采用Java语言开发的分布式应用性能监控系统,支持跟踪、监控和诊断分布式系统,特别是以微服务架构和云原生应用为代表的新一代大规模分布式系统,专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计。它提供了实时应用拓扑分析、应用性能指标监控、调用链路追踪、慢服务检测、性能优化建议等功能。
SkyWalking 功能
- 多种监控手段。可以通过语言探针和 service mesh 获得监控是数据。
- 多个语言自动探针。包括 Java、.NET Core、Node.JS、Go。
- 轻量高效。无需大数据平台,和大量的服务器资源。
- 模块化。UI、存储、集群管理都有多种机制可选。
- 支持告警。
- 优秀的可视化解决方案。
- 开源免费,社区活跃
用来解决什么问题
SkyWalking作为新一代APM系统,主要解决了以下几方面的问题:
-
分布式系统监控难题:在复杂的分布式系统中,调用链路蔓延多个服务,难以跟踪。SkyWalking提供了全链路追踪能力,可以清晰还原整个调用流程。
-
应用性能监控不足:很多系统对性能指标的监控不够全面和深入。SkyWalking可以从多个维度监控应用性能,找到瓶颈。
-
故障定位时间长:系统发生问题后,通过日志难以定位根因。而SkyWalking的追踪信息可以快速定位故障服务。
-
依赖关系复杂度高:微服务系统中间依赖关系错综复杂。SkyWalking提供服务拓扑 map,一目了然。
-
监控成本高:许多APM工具需要PAYLOAD接入,增加额外开销。SkyWalking使用无侵入式探针,减少系统侵入。
-
技术栈限制严重:旧监控系统只支持少数语言。SkyWalking提供Java、.NET等主流语言的探针。
-
监控视图单一:较老的APM系统UI功能简陋。SkyWalking提供丰富的时序图、拓扑图等可视化监控视图。
-
云原生支持不足:早期APM系统不支持新型微服务技术栈。SkyWalking在云原生支持上做了大量优化。
总之,SkyWalking作为新一代解决方案,很好地解决了传统APM系统在分布式链路跟踪和应用监控等方面的痛点,值得推荐使用。
SkyWalking 整体架构
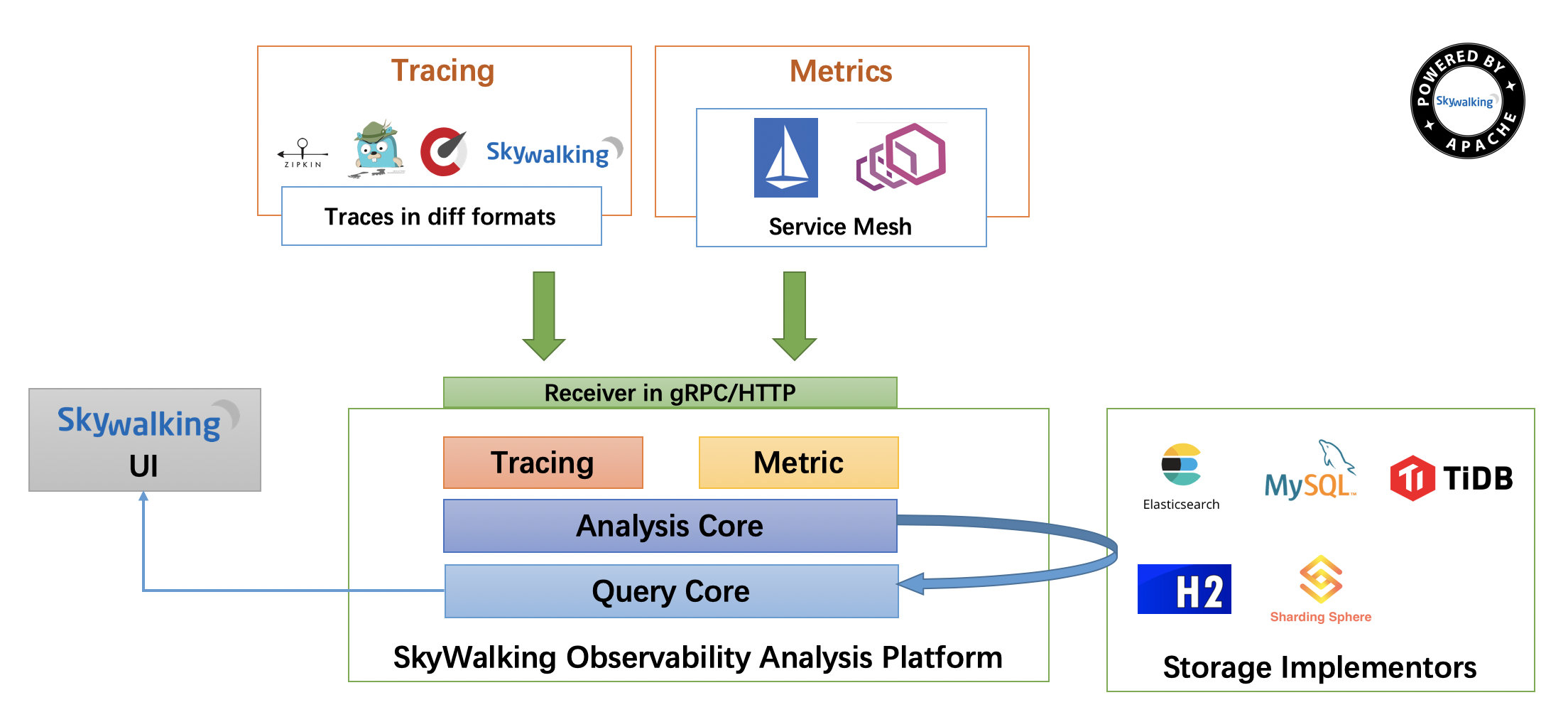
- 上部分 Agent :负责从应用中,收集链路信息,发送给 SkyWalking OAP 服务器。目前支持 SkyWalking、Zikpin、Jaeger 等提供的 Tracing 数据信息。而我们目前采用的是,SkyWalking Agent 收集 SkyWalking Tracing 数据,传递给服务器。
- 下部分 SkyWalking OAP :负责接收 Agent 发送的 Tracing 数据信息,然后进行分析(Analysis Core) ,存储到外部存储器( Storage ),最终提供查询( Query )功能。
- 右部分 Storage :Tracing 数据存储。目前支持 ES、MySQL、Sharding Sphere、TiDB、H2 多种存储器。而我们目前采用的是 ES ,主要考虑是 SkyWalking 开发团队自己的生产环境采用 ES 为主。
- 左部分 SkyWalking UI :负责提供控台,查看链路等等。
简单使用
1.安装单机环境
使用 Docker-compose 启动容器,我的服务器有点扛不住,所以使用本地虚拟机来运行,IP地址为10.211.55.50,系统使用的是CentOS Stream 9
version: "3"
services:
elasticsearch:
image: elasticsearch:8.4.2
container_name: elasticsearch
ports:
- "9200:9200"
healthcheck:
test: ["CMD-SHELL", "curl -sf http://localhost:9200/_cluster/health || exit 1"] #⼼跳检测,成功之后不再执⾏后⾯的退出
interval: 60s #⼼跳检测间隔周期
timeout: 10s
retries: 3
start_period: 60s #⾸次检测延迟时间
environment:
discovery.type: single-node #单节点模式
ingest.geoip.downloader.enabled: "false"
bootstrap.memory_lock: "true"
ES_JAVA_OPTS: "-Xms512m -Xmx512m"
TZ: "Asia/Shanghai"
xpack.security.enabled: "false" #单机模式
ulimits:
memlock:
soft: -1
hard: -1
skywalking-oap:
image: apache/skywalking-oap-server:9.3.0
container_name: skywalking-oap
depends_on:
elasticsearch:
condition: service_healthy
links:
- elasticsearch
environment:
SW_HEALTH_CHECKER: default
SW_STORAGE: elasticsearch
SW_STORAGE_ES_CLUSTER_NODES: 10.211.55.50:9200
JAVA_OPTS: "-Xms2048m -Xmx2048m"
TZ: Asia/Shanghai
SW_TELEMETRY: prometheus
healthcheck:
test: ["CMD-SHELL", "/skywalking/bin/swctl ch"]
interval: 30s
timeout: 10s
retries: 3
start_period: 10s
restart: on-failure
ports:
- "11800:11800"
- "12800:12800"
skywalking-ui:
image: apache/skywalking-ui:9.3.0
container_name: skywalking-ui
depends_on:
skywalking-oap:
condition: service_healthy
links:
- skywalking-oap
ports:
- "8080:8080"
environment:
SW_OAP_ADDRESS: http://10.211.55.50:12800
SW_HEALTH_CHECKER: default
TZ: Asia/Shanghai
healthcheck:
test: ["CMD-SHELL", "curl -sf http://localhost:8080 || exit 1"] #⼼跳检测,成功之后不再执⾏后⾯的退出
interval: 60s #⼼跳检测间隔周期
timeout: 10s
retries: 3
start_period: 60s #⾸次检测延迟时间
version: '3.8'
services:
elasticsearch:
# image: docker.elastic.co/elasticsearch/elasticsearch-oss:${ES_VERSION}
image: elasticsearch:7.9.0
container_name: elasticsearch
# --restart=always : 开机启动,失败也会一直重启;
# --restart=on-failure:10 : 表示最多重启10次
restart: always
ports:
- "9200:9200"
- "9300:9300"
healthcheck:
test: [ "CMD-SHELL", "curl --silent --fail localhost:9200/_cluster/health || exit 1" ]
interval: 30s
timeout: 10s
retries: 3
start_period: 10s
environment:
- discovery.type=single-node
# 锁定物理内存地址,防止elasticsearch内存被交换出去,也就是避免es使用swap交换分区,频繁的交换,会导致IOPS变高;
- bootstrap.memory_lock=true
# 设置时区
- TZ=Asia/Shanghai
# - "ES_JAVA_OPTS=-Xms512m -Xmx512m"
ulimits:
memlock:
soft: -1
hard: -1
oap:
image: apache/skywalking-oap-server:8.9.1
container_name: oap
restart: always
# 设置依赖的容器
depends_on:
elasticsearch:
condition: service_healthy
# 关联ES的容器,通过容器名字来找到相应容器,解决IP变动问题
links:
- elasticsearch
# 端口映射
ports:
- "11800:11800"
- "12800:12800"
# 监控检查
healthcheck:
test: [ "CMD-SHELL", "/skywalking/bin/swctl ch" ]
# 每间隔30秒执行一次
interval: 30s
# 健康检查命令运行超时时间,如果超过这个时间,本次健康检查就被视为失败;
timeout: 10s
# 当连续失败指定次数后,则将容器状态视为 unhealthy,默认 3 次。
retries: 3
# 应用的启动的初始化时间,在启动过程中的健康检查失效不会计入,默认 0 秒。
start_period: 10s
environment:
# 指定存储方式
SW_STORAGE: elasticsearch
# 指定存储的地址
SW_STORAGE_ES_CLUSTER_NODES: elasticsearch:9200
SW_HEALTH_CHECKER: default
SW_TELEMETRY: prometheus
TZ: Asia/Shanghai
# JAVA_OPTS: "-Xms2048m -Xmx2048m"
ui:
image: apache/skywalking-ui:8.9.1
container_name: skywalking-ui
restart: always
depends_on:
oap:
condition: service_healthy
links:
- oap
ports:
- "8088:8080"
environment:
SW_OAP_ADDRESS: http://oap:12800
TZ: Asia/Shanghai

访问 http://10.211.55.50:8080就能看到SkyWalking UI的面板了

2.下载 SkyWalking Agent
下载 SkyWalking Agent 地址:https://skywalking.apache.org/downloads/

# 下载完成后解压
tar xvf apache-skywalking-java-agent-9.1.0.tgz

3.项目引入SkyWalking Agent

在IDEA编辑运行配置增加虚拟机选项,如下所示
javaagent:上面下载的jar包的路径
Dskywalking.agent.service_name:服务组::服务名称
Dskywalking.collector.backend_service:SkyWalking地址
-javaagent:/Users/yovinchen/Desktop/project/skywalking-agent/skywalking-agent.jar
-Dskywalking.agent.service_name=ms::xlcs-parent-service-acl
-Dskywalking.collector.backend_service=10.211.55.50:11800
然后运行项目就能够在SkyWalking UI中看到服务
功能介绍
普通服务
服务
Service 服务
首页中展示的是现有的服务项
- Service Groups(服务组): 将服务按照某种逻辑分组的方式展示,有助于对大型系统中服务的管理和监控。
- Service Names(服务名称): 表示不同的服务单元或模块的名称,每个服务都会有一个唯一的服务名称用于标识。
- Load (calls / min)(负载 - 调用次数 / 分钟): 指每个服务单位时间内的调用次数,反映了服务的负载情况。
- Success Rate (%)(成功率): 表示服务成功处理的请求在总请求数中的比率,以百分比形式表示。
- Latency (ms)(延迟): 表示服务处理请求所需的时间,通常以毫秒为单位。
- Apdex(应用程序性能指数): 是一种度量应用程序性能的指标,基于用户对延迟的感知。它将用户体验划分为满意、可容忍和不满意三个级别,通过比较满意请求的数量和所有请求的总数,计算出一个衡量应用性能的指数。
Topology 拓扑结构

展示的是该项目调用的拓扑结构图,可以清楚的看到各服务之间的调用情况
Trace 链路追踪

在这里可以通过查询查看详细程序的调用链路、详细的调用时间、调用的模块、我们可以通过这些信息判断出哪一个服务/SQL查询比较慢进而去优化。
下面是一些不同的展示方式便于分析问题



Log 日志

虚拟数据库
SkyWalking 可以通过分析项目中的调用情况推断出相应的数据库

- Service Names(服务名称): 在虚拟数据库中,可能指代不同数据库或数据库集群的特定名称,用于标识和区分各个数据库服务单元。
- Latency (ms)(延迟): 表示在处理请求时所需的时间,以毫秒为单位。对于数据库而言,延迟可能表示执行查询、读取或写入数据所需的时间。
- Successful Rate (%)(成功率): 表示成功执行的请求在总请求数中的比率,用百分比表示。对于数据库,可能表示成功完成查询或事务的比率。
- Traffic (calls / min)(流量 - 调用次数 / 分钟): 指代在一分钟内数据库所收到的请求或调用次数。这可能包括查询、写入或其他与数据库相关的操作。
虚拟缓存
SkyWalking 可以通过分析项目中的调用情况推断出相应的缓存

- Service Names(服务名称): 在虚拟缓存中,这可能是不同缓存服务或缓存集群的特定名称,用于标识和区分各个缓存服务单元。
- Access Latency (ms)(访问延迟): 表示从缓存中获取数据所需的时间,通常以毫秒为单位。这是指从发出请求到获得所需数据的时间。
- Successful Access Rate (%)(成功访问率): 表示从缓存成功获取数据的请求在总请求数中的比率,以百分比表示。对于缓存而言,这代表着有效利用缓存的程度。
- Access Traffic (calls / min)(访问流量 - 调用次数 / 分钟): 表示在一分钟内针对缓存的访问请求次数。这可能包括读取、写入或其他缓存操作的总次数。
虚拟消息队列
SkyWalking 可以通过分析项目中的调用情况推断出相应的消息队列

- Service Names(服务名称): 这指代不同的服务单元或者模块的名称,每个服务可能是消息队列的一个实例,消费者、生产者或者其他与消息传递相关的组件。
- Transmission Latency (ms)(传输延迟): 表示消息从生产者发送到消费者接收所需的时间。这个指标衡量了消息在系统中传输的速度,通常以毫秒为单位。
- Consume Successful Rate (%)(消费成功率): 表示消费者成功接收并处理消息的比率,即成功消费的消息数量占总消息量的百分比。
- Consume Traffic (calls / min)(消费流量 - 调用次数 / 分钟): 表示消费者消费消息的频率,即消费者在一分钟内处理的消息数量。
- Produce Successful Rate (%)(生产成功率): 表示生产者成功将消息发送到消息队列或者系统中的比率,即成功发送的消息数量占总发送消息量的百分比。
- Produce Traffic (calls / min)(生产流量 - 调用次数 / 分钟): 表示生产者向消息队列或者系统发送消息的频率,即在一分钟内发送的消息数量。
基础设施
linux
SkyWalking 可以实现监控 Linux 系统情况

Linux服务器接入SkyWalking需要两个工具:
node_exporter pentelemetry-collector
https://github.com/prometheus/node_exporter/releases
wget -i https://github.com/prometheus/node_exporter/releases/download/v1.7.0/node_exporter-1.7.0.linux-arm64.tar.gz
通过命令解压
tar -xvf node_exporter-1.7.0.linux-arm64.tar.gz
创建一个系统服务,让node_exporter能够开机自启并通过系统管控
vim /etc/systemd/system/node_exporter.service
[Unit]
Description=node exporter service
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
User=root
Group=root
ExecStart=/root/node_exporter-1.7.0.linux-arm64/node_exporter #这里是node_exporter的解压地址
Restart=on-failure
[Install]
WantedBy=multi-user.target
执行命令刷新系统服务
systemctl daemon-reload
开启node_exporter服务
systemctl start node_exporter
这里服务默认监听9100端口,请勿占用,就完成了node_exporter的安装